고정 헤더 영역
상세 컨텐츠
본문
반응형
1. Policy Gradient Theorem
Policy Gradient Theorem은 정책 기반 강화학습에서 에이전트의 정책(policy)을 어떻게 개선해야 하는지를 수학적으로 설명하는 정리입니다. 이 정리에 따르면 에이전트가 더 많은 보상을 얻도록 정책을 업데이트하려면, 특정 상태에서 어떤 행동을 선택할 확률(정책)의 로그 확률에 그 행동의 가치(Q값 또는 return)를 곱한 방향으로 정책 파라미터를 조정하면 됩니다. 즉, 에이전트가 실제로 높은 보상을 얻은 행동의 확률은 높이고 낮은 보상을 얻은 행동의 확률은 낮추도록 정책을 업데이트하는 원리를 제공합니다. 이러한 방식은 환경의 모델을 알 필요 없이 경험으로부터 직접 정책을 학습할 수 있게 해주며, REINFORCE, Actor-Critic 등 다양한 정책 기반 강화학습 알고리즘의 이론적 기반이 됩니다.
1. 왜 Policy Gradient Theorem이 필요할까?
강화학습에는 크게 두 가지 접근이 있습니다.
- 가치 기반(Value-Based)
행동의 가치(Q값)를 계산해서 가장 큰 행동을 고르는 방식
예: Q-learning, DQN - 정책 기반(Policy-Based)
행동의 가치를 먼저 계산하는 것이 아니라, 행동을 선택하는 규칙 자체를 직접 학습하는 방식
예: REINFORCE, Policy Gradient, PPO
정책 기반 방법에서는 다음과 같은 질문이 생깁니다.
정책을 더 좋은 방향으로 바꾸려면
정확히 어떻게 업데이트해야 할까?
이 질문에 대한 답을 주는 것이 바로 Policy Gradient Theorem입니다.
2. Policy Gradient Theorem의 핵심 수식

∇θJ(θ) : 정책을 더 좋은 방향으로 바꾸기 위한 기울기입니다. “정책을 어느 방향으로 수정하면 보상이 커질까?”를 의미합니다.
logπθ(a∣s): 현재 상태에서 실제로 선택한 행동의 로그 확률입니다. 선택한 행동의 확률을 조절하기 위한 수학적 도구라고 이해하면 됩니다.
∇θlogπθ(a∣s): 정책 파라미터를 조금 바꿨을 때 그 행동의 선택 확률이 얼마나 변하는지를 나타냅니다. 정책의 민감도라고 볼 수 있습니다.
Qπ(s,a): 상태 s에서 행동 a를 했을 때 앞으로 받을 것으로 기대되는 보상입니다.
💬 수식에 로그(log)가 들어간 이유
이유는 수학적으로 미분을 쉽게 만들기 위해서입니다. 특히 확률의 곱을 다룰 때 로그를 취하면 덧셈으로 바뀌어서 계산이 훨씬 편해집니다.
2. REINFORCE 알고리즘
REINFORCE 알고리즘은 정책 기반 강화학습의 가장 기본적인 알고리즘으로, 에이전트가 에피소드 동안 수행한 행동들의 결과를 바탕으로 정책을 직접 업데이트하는 방법입니다. 에이전트는 한 에피소드를 끝까지 실행한 뒤 각 시점에서 선택한 행동의 로그 확률에 그 이후에 얻은 총 보상(Return)을 곱한 값을 이용해 정책 파라미터를 조정합니다. 이 과정은 높은 보상을 가져온 행동의 선택 확률은 높이고 낮은 보상을 가져온 행동의 확률은 낮추는 방향으로 정책을 수정하게 하며, 이러한 방식은 Policy Gradient Theorem을 실제 학습 알고리즘 형태로 구현한 대표적인 예라고 할 수 있습니다.
1. REINFORCE 알고리즘의 동작 과정
REINFORCE는 다음과 같은 과정을 반복합니다.
1단계: 에이전트가 정책에 따라 행동합니다.
2단계: 에피소드가 끝날 때까지 환경과 상호작용합니다.
3단계: 각 시점에서 얻은 총 보상(Return) 을 계산합니다.
4단계: 그 보상을 이용해 정책을 업데이트합니다.2. Retrun
REINFORCE에서는 Return을 사용합니다. Return은 다음과 같이 정의됩니다.
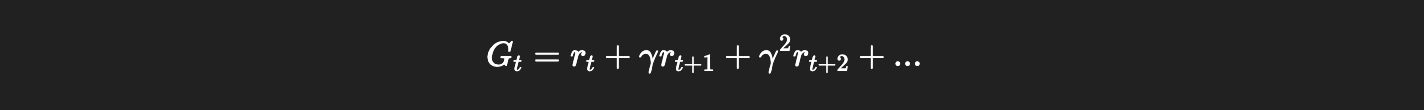
특정 시점 이후에 얻은 모든 보상의 합

3. REINFORCE 업데이트 수식
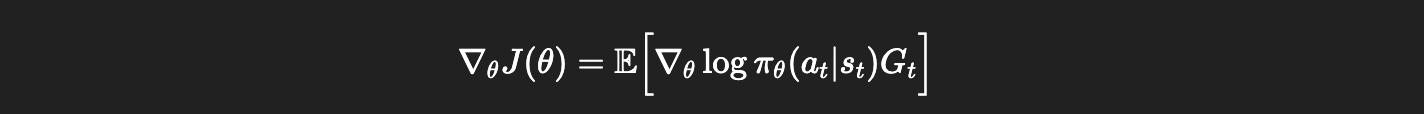
- 실제로 선택한 행동의 확률을 기반으로 그 행동 이후 얻은 총 보상(Return) 을 곱해서 정책을 업데이트합니다.
- 보상이 큰 행동은 확률을 높이고 보상이 작은 행동은 확률을 낮춥니다.
4. REINFORCE 알고리즘 의사코드
정책 파라미터 θ 초기화
반복:
에피소드 실행
(s0,a0,r0),(s1,a1,r1),... 수집
각 시간 t에 대해
Return Gt 계산
정책 업데이트
θ ← θ + α * ∇θ log πθ(at|st) * Gt
import gym
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
#Hyperparameters
learning_rate = 0.0002
gamma = 0.98
class Policy(nn.Module):
def __init__(self):
super(Policy, self).__init__()
self.data = []
self.fc1 = nn.Linear(4, 128)
self.fc2 = nn.Linear(128, 2)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.softmax(self.fc2(x), dim=0)
return x
def put_data(self, item):
self.data.append(item)
def train_net(self):
R = 0
self.optimizer.zero_grad()
for r, prob in self.data[::-1]:
R = r + gamma * R
loss = -torch.log(prob) * R
loss.backward()
self.optimizer.step()
self.data = []
def main():
env = gym.make('CartPole-v1')
pi = Policy()
score = 0.0
print_interval = 20
for n_epi in range(10000):
s, _ = env.reset()
done = False
while not done: # CartPole-v1 forced to terminates at 500 step.
prob = pi(torch.from_numpy(s).float())
m = Categorical(prob)
a = m.sample()
s_prime, r, done, truncated, info = env.step(a.item())
pi.put_data((r,prob[a]))
s = s_prime
score += r
pi.train_net()
if n_epi%print_interval==0 and n_epi!=0:
print("# of episode :{}, avg score : {}".format(n_epi, score/print_interval))
score = 0.0
env.close()
if __name__ == '__main__':
main()
3. Actor-Critic
강화학습에는 크게 가치 기반(Value-Based) 방법과 정책 기반(Policy-Based) 방법이 있습니다. 가치 기반 방법은 행동의 가치를 계산한 뒤 가장 좋은 행동을 선택하고, 정책 기반 방법은 행동을 선택하는 규칙 자체를 직접 학습합니다. Actor-Critic은 이 두 방법의 장점을 결합한 방식으로, 행동을 선택하는 Actor와 그 행동이 얼마나 좋았는지 평가하는 Critic이 함께 학습하는 구조입니다. 쉽게 말하면 Actor는 “무엇을 할까?”를 결정하고, Critic은 “방금 한 선택이 얼마나 좋았을까?”를 평가합니다. 그래서 Actor-Critic은 정책 기반의 유연함과 가치 기반의 평가 능력을 동시에 활용할 수 있는 강화학습 방법입니다.
1. Actor와 Critic
Actor란?
Actor는 행동을 선택하는 역할을 합니다. 현재 상태를 보고 어떤 행동을 할지 결정하는 부분입니다. 수식으로는 보통 정책으로 표현합니다.

Critic이란?
Critic은 평가하는 역할을 합니다. 현재 상태가 얼마나 좋은지 혹은 방금 선택한 행동이 얼마나 괜찮았는지를 평가합니다. Critic은 보통 다음 중 하나를 학습합니다.
- 상태 가치 함수 V(s)
- 행동 가치 함수 Q(s,a)
즉, Critic은 가치 함수(Value Function) 를 학습합니다.
2. Actor-Critic의 전체 흐름
현재 상태 s 관찰
→ Actor가 행동 a 선택
→ 환경이 보상 r, 다음 상태 s' 반환
→ Critic이 현재 상태와 결과를 평가
→ Actor는 그 평가를 바탕으로 정책 수정
→ Critic도 자신의 가치 추정을 수정- Actor는 행동을 더 잘 선택하도록 학습하고
- Critic은 평가를 더 정확하게 하도록 학습합니다.
둘이 동시에 발전합니다.
3. Critic이 왜 필요할까?
정책 기반 방법에서는 보통 좋은 행동의 확률을 높이고 나쁜 행동의 확률을 낮추도록 학습합니다. 그런데 여기서 중요한 질문이 생깁니다.
방금 한 행동이 좋은 행동인지 나쁜 행동인지
어떻게 판단할까?
REINFORCE 같은 기본 정책 기반 방법은 에피소드가 끝난 뒤 총 보상(Return) 을 보고 판단합니다. 하지만 이 방식은 느리고, 보상의 변동이 커서 학습이 흔들릴 수 있습니다. 그래서 Critic이 필요합니다. Critic은 현재 상태나 행동의 가치를 추정해서 Actor에게 이렇게 말해줍니다.
“방금 행동은 예상보다 좋았어”
“방금 행동은 예상보다 별로였어”
이런 평가가 있으면 Actor는 훨씬 안정적으로 학습할 수 있습니다.
4. TD Error
Actor-Critic에서는 Critic이 보통 TD Error(Temporal Difference Error) 를 이용해 평가합니다. 수식은 다음과 같습니다.

처음 보면 어려워 보이지만 의미는 단순합니다.
- V(s): 원래 내가 생각하던 현재 상태의 가치
- r+γV(s′): 실제로 경험해보니 얻은 값
즉, 실제로 관찰한 값−원래 예상한 값입니다. 이 차이를 TD Error 라고 부릅니다.
TD Error가 양수이면 실제 결과가 예상보다 좋았다는 뜻입니다.
“방금 행동 괜찮았네.
앞으로 이 행동을 더 자주 하자.”
그래서 Actor는 방금 선택한 행동의 확률을 높이는 방향으로 학습합니다.
TD Error가 음수이면 실제 결과가 예상보다 나빴다는 뜻입니다.
“방금 행동은 생각보다 별로였네.
앞으로 이 행동은 덜 하자.”
그래서 Actor는 그 행동의 확률을 낮추는 방향으로 학습합니다.
5. Actor의 학습
Actor는 정책을 학습합니다. 예를 들어 Actor가 신경망이라면 구조는 다음과 같습니다.
state → neural network → action probabilities
예를 들어 출력이
[0.1, 0.7, 0.2]라고 하면 의미는 다음과 같습니다.
- 행동 1 선택 확률 10%
- 행동 2 선택 확률 70%
- 행동 3 선택 확률 20%
이때 Critic이 “방금 행동 2는 정말 좋았어”라고 평가하면 Actor는 행동 2의 확률을 더 높이도록 학습합니다.
6. Critic의 학습
Critic은 가치 함수를 학습합니다. 예를 들어 상태 가치 함수 V(s)를 학습하는 경우 구조는 다음과 같습니다.
state → neural network → V(s)Critic은 현재 상태가 얼마나 좋은 상태인지 숫자로 예측합니다. 그리고 실제 경험한 보상과 다음 상태를 참고해서 그 예측을 점점 더 정확하게 고칩니다. 즉 Critic은 평가 기준을 더 정확하게 만드는 역할을 합니다.
7. Actor-Critic 구조
상태 s
↓
Actor → 행동 a 선택
↓
환경 → 보상 r, 다음 상태 s'
↓
Critic → 평가(TD Error 계산)
↓
Actor 업데이트 / Critic 업데이트- Actor는 선택하고
- Critic은 평가하고
- 두 모델이 함께 개선됩니다.
8. Actor-Critic의 장점
1) 정책 기반보다 더 안정적이다
Critic이 평가를 도와주기 때문에 Actor가 막연하게 학습하지 않습니다. 그래서 REINFORCE보다 안정적인 경우가 많습니다.
2) 연속 행동 문제에 적합하다
자동차 조향, 로봇 제어처럼 행동이 연속적일 때 잘 작동합니다.
3) 실제로 매우 많이 사용된다
현대 강화학습에서 많이 쓰이는 알고리즘인 A2C, A3C, PPO, DDPG, SAC 등이 모두 Actor-Critic 계열입니다.
9. Q 액터 크리틱
Q Actor-Critic은 Actor-Critic 구조에서 Critic이 상태 가치 V(s) 대신 행동 가치 함수 Q(s,a) 를 학습하여 Actor의 정책을 업데이트하는 강화학습 방법입니다. Actor는 상태를 보고 어떤 행동을 선택할지 결정하는 정책 π(a∣s)을 학습하고, Critic은 해당 상태와 행동의 조합이 얼마나 좋은지를 나타내는 Q값을 추정합니다. Actor는 Critic이 계산한 Q값을 참고하여 높은 Q값을 가지는 행동의 선택 확률은 높이고 낮은 Q값을 가지는 행동의 확률은 낮추도록 정책을 업데이트하게 됩니다. 즉, Q Actor-Critic은 정책 기반 학습과 가치 기반 평가를 결합하여, 행동의 가치를 직접 활용해 정책을 보다 효율적으로 개선하도록 하는 Actor-Critic 구조의 한 형태입니다.
10. 어드벤티지 액터 크리틱
Advantage Actor-Critic(A2C)은 Actor-Critic 구조에서 행동의 가치 Q(s,a)를 그대로 사용하는 대신, 어드벤티지(Advantage) 값을 이용해 정책을 업데이트하는 강화학습 방법입니다. 어드벤티지는 특정 행동이 해당 상태의 평균적인 행동보다 얼마나 더 좋은지를 나타내는 값으로, 보통 A(s,a)=Q(s,a)−V(s) 형태로 계산됩니다. Actor는 이 어드벤티지 값을 이용해 평균보다 더 좋은 행동의 선택 확률은 높이고 평균보다 나쁜 행동의 확률은 낮추도록 정책을 업데이트하며, Critic은 상태 가치 함수 V(s)를 학습하여 어드벤티지를 계산하는 데 필요한 기준을 제공합니다. 이러한 방식은 불필요한 분산을 줄이고 정책 업데이트를 더 안정적으로 만들어 Actor-Critic 학습을 보다 효율적으로 수행할 수 있게 합니다.
11. TD 액터 크리틱
TD Actor-Critic은 Actor-Critic 구조에서 Critic이 상태 가치 V(s)를 학습할 때 Temporal Difference(TD) 학습을 이용해 행동을 평가하는 강화학습 방법입니다. Actor는 상태를 입력받아 어떤 행동을 선택할지 결정하는 정책을 학습하고, Critic은 보상과 다음 상태의 가치 r+γV(s′)를 이용해 현재 상태의 가치 V(s)를 업데이트하며 그 차이를 TD Error로 계산합니다. 이 TD Error는 방금 선택한 행동이 예상보다 좋았는지 나빴는지를 나타내는 신호로 사용되며, Actor는 이 값을 이용해 좋은 행동의 선택 확률은 높이고 나쁜 행동의 확률은 낮추도록 정책을 수정합니다. 즉 TD Actor-Critic은 에피소드가 끝날 때까지 기다리지 않고 매 스텝마다 Critic의 평가(TD Error)를 이용해 정책을 업데이트할 수 있어 학습 속도와 안정성이 향상된 Actor-Critic 방법입니다.
import gymnasium as gym
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
from torch.distributions import Categorical
#Hyperparameters
learning_rate = 0.0002
gamma = 0.98
n_rollout = 10
class ActorCritic(nn.Module):
def __init__(self):
super(ActorCritic, self).__init__()
self.data = []
self.fc1 = nn.Linear(4,256)
self.fc_pi = nn.Linear(256,2)
self.fc_v = nn.Linear(256,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, softmax_dim = 0):
x = F.relu(self.fc1(x))
x = self.fc_pi(x)
prob = F.softmax(x, dim=softmax_dim)
return prob
def v(self, x):
x = F.relu(self.fc1(x))
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
s_lst, a_lst, r_lst, s_prime_lst, done_lst = [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r / 100.0])
s_prime_lst.append(s_prime)
done_mask = 0.0 if done else 1.0
done_lst.append([done_mask])
s_batch = torch.tensor(np.array(s_lst), dtype=torch.float)
a_batch = torch.tensor(np.array(a_lst), dtype=torch.long)
r_batch = torch.tensor(np.array(r_lst), dtype=torch.float)
s_prime_batch = torch.tensor(np.array(s_prime_lst), dtype=torch.float)
done_batch = torch.tensor(np.array(done_lst), dtype=torch.float)
self.data = []
return s_batch, a_batch, r_batch, s_prime_batch, done_batch
def train_net(self):
s, a, r, s_prime, done = self.make_batch()
td_target = r + gamma * self.v(s_prime) * done
delta = td_target - self.v(s)
pi = self.pi(s, softmax_dim=1)
pi_a = pi.gather(1,a)
loss = -torch.log(pi_a) * delta.detach() + F.smooth_l1_loss(self.v(s), td_target.detach())
self.optimizer.zero_grad()
loss.mean().backward()
self.optimizer.step()
def main():
env = gym.make('CartPole-v1')
model = ActorCritic()
print_interval = 20
score = 0.0
for n_epi in range(10000):
done = False
s, _ = env.reset()
while not done:
for t in range(n_rollout):
prob = model.pi(torch.from_numpy(s).float())
m = Categorical(prob)
a = m.sample().item()
s_prime, r, done, truncated, info = env.step(a)
model.put_data((s,a,r,s_prime,done))
s = s_prime
score += r
if done:
break
model.train_net()
if n_epi%print_interval==0 and n_epi!=0:
print("# of episode :{}, avg score : {:.1f}".format(n_epi, score/print_interval))
score = 0.0
env.close()
if __name__ == '__main__':
main()
반응형
'인공지능 > 강화학습' 카테고리의 다른 글
| Q-learning (0) | 2026.03.11 |
|---|---|
| Deep RL (0) | 2026.03.11 |
| TD Learning (0) | 2026.03.10 |
| Monte Carlo Learning (0) | 2026.03.09 |
| 벨만기대방정식 (0) | 2026.03.05 |




