고정 헤더 영역
상세 컨텐츠
본문
반응형
1. Q-learning
Q-learning은 강화학습에서 각 상태에서 어떤 행동이 얼마나 좋은지를 점수(Q-value)로 학습하는 방법입니다. 에이전트는 환경과 상호작용하면서 행동을 해보고 받은 보상을 바탕으로 행동의 점수를 조금씩 수정하게 됩니다. 이 과정을 반복하면 좋은 행동의 점수는 높아지고 좋지 않은 행동의 점수는 낮아지며, 결국 에이전트는 각 상태에서 가장 높은 점수를 가진 행동을 선택하게 됩니다. 이러한 방식 때문에 Q-learning은 대표적인 가치 기반(Value-Based) 강화학습 알고리즘으로 알려져 있습니다. [논문]
1. Q값(Q-value)
Q-learning에서 가장 중요한 개념은 Q값(Q-value) 입니다.
Q(s,a)
- s : 현재 상태(State)
- a : 행동(Action)
현재 상태에서 특정 행동을 했을 때 앞으로 받을 것으로 기대되는 보상
2. Q-learning이 작동하는 방식
Q-learning의 학습 과정은 다음과 같이 이루어집니다.
1️⃣ 현재 상태를 확인합니다.
2️⃣ 가능한 행동 중 하나를 선택합니다.
3️⃣ 행동을 수행합니다.
4️⃣ 보상(reward)을 받습니다.
5️⃣ 다음 상태로 이동합니다.
6️⃣ 방금 한 행동의 Q값을 수정합니다.
이 과정을 계속 반복하면서 에이전트는 점점 더 좋은 행동을 학습하게 됩니다.
3. Q-learning의 핵심 수식
Q-learning은 다음과 같은 방식으로 Q값을 업데이트합니다.


현재 행동의 가치를
현재 보상 + 다음 상태의 최대 미래 가치를 이용하여 수정하는 과정입니다.
다음과 같은 간단한 환경을 생각해보겠습니다.
S . . . G
0 1 2 3 4설정
- 시작 상태 : 0
- 목표 상태 : 4
- 목표 도착 보상 : +10
- 이동 보상 : -1
행동
- 왼쪽 이동
- 오른쪽 이동
초기 상태 처음에는 모든 Q값이 0이라고 가정합니다.
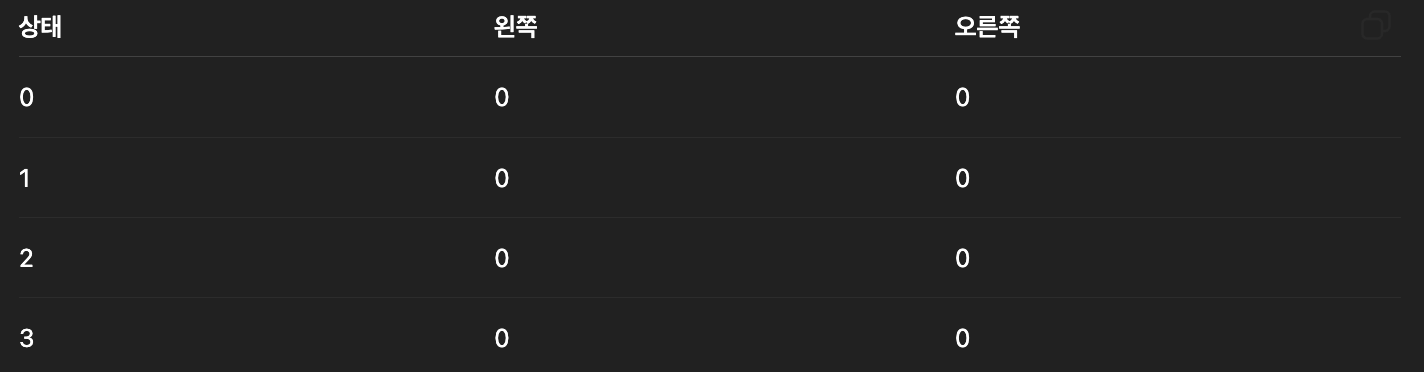
예제 1 : 상태 3에서 오른쪽 이동
현재 상태: s = 3
행동: a = 오른쪽
이동 결과: 3 → 4 (Goal)
보상: r = +10
다음 상태: s' = 4
파라미터 설정
α (학습률) = 0.1
γ (할인율) = 0.9
Goal 상태는 종료 상태(terminal state) 입니다. 따라서 움직일 수 없으므로 아래와 같습니다.
max Q(s',a') = 0
목표값 계산

값을 대입하면 =10

업데이트 결과

상태 3에서 오른쪽 행동의 가치가 1로 증가했습니다.
2. Gym
Gym(OpenAI Gym)은 강화학습 알고리즘을 실험하고 개발할 수 있도록 다양한 환경(environment)을 제공하는 파이썬 라이브러리입니다. 연구자나 개발자는 Gym을 이용하여 에이전트(agent)가 환경과 상호작용하며 행동(action)을 선택하고 보상(reward)을 받는 과정을 쉽게 구현할 수 있습니다. Gym은 CartPole, MountainCar, Atari 게임 등 다양한 표준 환경을 제공하여 강화학습 알고리즘을 비교하고 테스트하기에 적합하며, 대부분의 강화학습 연구와 실습에서 기본적인 실험 플랫폼으로 널리 사용됩니다.
import gym
import collections
import random
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
#Hyperparameters
learning_rate = 0.0005
gamma = 0.98
buffer_limit = 50000
batch_size = 32
class ReplayBuffer():
def __init__(self):
self.buffer = collections.deque(maxlen=buffer_limit)
def put(self, transition):
self.buffer.append(transition)
def sample(self, n):
mini_batch = random.sample(self.buffer, n)
s_lst, a_lst, r_lst, s_prime_lst, done_mask_lst = [], [], [], [], []
for transition in mini_batch:
s, a, r, s_prime, done_mask = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
done_mask_lst.append([done_mask])
return torch.tensor(s_lst, dtype=torch.float), torch.tensor(a_lst), \
torch.tensor(r_lst), torch.tensor(s_prime_lst, dtype=torch.float), \
torch.tensor(done_mask_lst)
def size(self):
return len(self.buffer)
class Qnet(nn.Module):
def __init__(self):
super(Qnet, self).__init__()
self.fc1 = nn.Linear(4, 128)
self.fc2 = nn.Linear(128, 128)
self.fc3 = nn.Linear(128, 2)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def sample_action(self, obs, epsilon):
out = self.forward(obs)
coin = random.random()
if coin < epsilon:
return random.randint(0,1)
else :
return out.argmax().item()
def train(q, q_target, memory, optimizer):
for i in range(10):
s,a,r,s_prime,done_mask = memory.sample(batch_size)
q_out = q(s)
q_a = q_out.gather(1,a)
max_q_prime = q_target(s_prime).max(1)[0].unsqueeze(1)
target = r + gamma * max_q_prime * done_mask
loss = F.smooth_l1_loss(q_a, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
def main():
env = gym.make('CartPole-v1')
q = Qnet()
q_target = Qnet()
q_target.load_state_dict(q.state_dict())
memory = ReplayBuffer()
print_interval = 20
score = 0.0
optimizer = optim.Adam(q.parameters(), lr=learning_rate)
for n_epi in range(10000):
epsilon = max(0.01, 0.08 - 0.01*(n_epi/200)) #Linear annealing from 8% to 1%
s, _ = env.reset()
done = False
while not done:
a = q.sample_action(torch.from_numpy(s).float(), epsilon)
s_prime, r, done, truncated, info = env.step(a)
done_mask = 0.0 if done else 1.0
memory.put((s,a,r/100.0,s_prime, done_mask))
s = s_prime
score += r
if done:
break
if memory.size()>2000:
train(q, q_target, memory, optimizer)
if n_epi%print_interval==0 and n_epi!=0:
q_target.load_state_dict(q.state_dict())
print("n_episode :{}, score : {:.1f}, n_buffer : {}, eps : {:.1f}%".format(
n_epi, score/print_interval, memory.size(), epsilon*100))
score = 0.0
env.close()
if __name__ == '__main__':
main()반응형
'인공지능 > 강화학습' 카테고리의 다른 글
| Policy 기반 에이전트 (0) | 2026.03.12 |
|---|---|
| Deep RL (0) | 2026.03.11 |
| TD Learning (0) | 2026.03.10 |
| Monte Carlo Learning (0) | 2026.03.09 |
| 벨만기대방정식 (0) | 2026.03.05 |




