고정 헤더 영역
상세 컨텐츠
본문
반응형
1. 근사
근사(Approximation)란 상태나 행동의 수가 너무 많아 모든 경우의 값을 정확히 계산하거나 저장하기 어려울 때, 함수나 모델을 이용해 그 값을 비슷하게 추정하는 방법을 의미합니다. 예를 들어 상태가 몇 개 안 되는 작은 문제에서는 각 상태의 가치(Value)를 표(table)로 모두 저장할 수 있지만, 실제 문제처럼 상태가 매우 많거나 연속적인 경우에는 이를 전부 저장하는 것이 불가능합니다. 이때 신경망이나 수학적 함수 같은 모델을 사용하여 여러 상태의 공통된 패턴을 학습하고, 정확한 값 대신 그에 가까운 값을 예측하도록 하는 것을 근사라고 합니다. 즉, 근사는 모든 값을 정확히 계산하기보다는 복잡한 문제를 해결하기 위해 현실적으로 계산 가능한 범위에서 값을 추정하는 방법이라고 이해할 수 있습니다.
1. 바둑의 상태 수
바둑의 상태 수는 정확히 계산하기는 어렵지만, 일반적으로 약 10^ 정도로 추정됩니다. 이는 바둑판의 모든 가능한 돌 배치를 고려했을 때 나올 수 있는 상태의 수를 의미합니다. 바둑은 19×19 크기의 판을 사용하므로 총 361개의 교차점이 있고, 각 위치에는 흑돌, 백돌, 빈 칸 세 가지 상태가 올 수 있습니다. 단순하게 생각하면 가능한 경우의 수는 3^이 되는데, 이는 약 10^ 정도의 매우 큰 수입니다. 실제 바둑 규칙에서는 자충수나 금수 같은 불가능한 상태들이 있기 때문에 이보다 조금 적지만, 여전히 약 10^ 수준의 엄청난 상태 공간을 갖는 것으로 알려져 있습니다. 이러한 이유 때문에 바둑에서는 모든 상태의 가치를 테이블로 저장하는 것이 불가능합니다.
2. 상태 공간이 매우 큰 문제들
체스
체스는 8×8 보드 위에서 여러 종류의 말이 움직이기 때문에 가능한 상태의 수가 약 10^ 정도로 추정됩니다. 이 역시 모든 상태의 가치를 테이블로 저장하기에는 너무 큰 수입니다.
자율주행 자동차
자율주행에서는 상태가 단순히 “현재 위치” 하나가 아니라 차량의 위치, 속도, 주변 차량 위치, 보행자, 신호등, 도로 상황, 센서 데이터 등 수많은 요소로 구성됩니다. 이러한 상태들은 대부분 연속값(continuous value)이기 때문에 가능한 상태의 수가 사실상 무한대에 가깝습니다.
로봇 제어
로봇 팔의 각도, 속도, 힘, 센서 값 등이 모두 상태가 되며, 이 값들은 연속적인 값입니다. 따라서 상태 공간이 매우 크고 테이블 방식으로 저장할 수 없습니다.
비디오 게임
예를 들어 Atari 게임에서는 화면 자체가 상태가 됩니다. 만약 84×84 픽셀의 이미지를 상태로 사용한다면 각 픽셀 값 조합이 상태가 되기 때문에 가능한 상태 수가 천문학적으로 커집니다.
3. 모든 상태의 가치를 저장할 수 없다면?
강화학습에서 바둑이나 자율주행처럼 상태의 수가 너무 많아 테이블(Tabular)로 모든 상태의 가치를 저장할 수 없는 문제는 보통 함수 근사(Function Approximation) 방법을 사용해 해결합니다. 즉, 각 상태의 가치를 하나씩 저장하는 대신, 수학적 함수나 모델을 이용해 상태의 특징을 학습하고 그 상태의 가치나 행동 가치를 예측하도록 만드는 방식입니다. 예를 들어 선형 함수나 결정트리 같은 모델을 사용할 수도 있지만, 상태가 매우 복잡한 문제에서는 보통 딥러닝 기반 신경망(Neural Network)을 사용합니다. 신경망은 많은 상태 데이터를 학습하면서 상태와 가치 사이의 패턴을 발견하고, 새로운 상태가 들어왔을 때도 그 가치를 근사적으로 예측할 수 있습니다. 이렇게 하면 모든 경우를 저장할 필요 없이, 하나의 모델이 다양한 상태의 가치를 일반화하여 추정할 수 있기 때문에 대규모 상태 공간 문제를 해결할 수 있습니다.
2. 함수 근사가 필요한 이유
1. 테이블에 저장하는 방식
예를 들어 상태가 몇 개 안 되는 문제라면 다음처럼 저장할 수 있습니다.

V = {
"A": 0.5,
"B": 0.0,
"C": -0.5
}이처럼 상태가 적을 때는 각 상태의 값을 직접 저장하는 Tabular 방식이 잘 작동합니다. 하지만 현실 문제에서는 테이블 방식이 불가능합니다. 문제는 현실의 강화학습 문제에서는 상태의 수가 매우 많다는 것입니다.
2. 함수 근사
이 문제를 해결하기 위해 사용하는 방법이 함수 근사(Function Approximation) 입니다. 핵심 아이디어는 다음과 같습니다.
상태마다 값을 저장하는 대신
상태가 들어오면 그 상태의 가치를 계산하는 함수를 학습한다.

예를 들어 상태가 숫자 하나라고 가정해 보겠습니다. 함수를 다음처럼 만들 수 있습니다.
V(s)=w×s
- s : 상태
- w : 학습되는 파라미터
w = 0.5
def V(s):
return w * s
이렇게 하면 상태 값이 들어올 때마다 계산으로 가치가 결정됩니다. 즉, 테이블처럼 값을 저장하는 것이 아니라 함수를 이용해 계산하는 방식입니다.
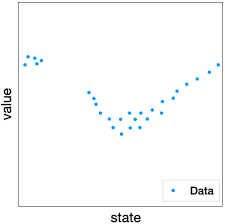
피팅
피팅(Fitting)은 데이터에 맞도록 모델이나 함수를 조정하는 과정을 의미합니다. 즉, 주어진 데이터의 입력과 출력 사이의 관계를 가장 잘 설명하도록 함수의 파라미터(계수나 가중치)를 학습시키는 것입니다. 예를 들어 여러 데이터 점이 있을 때 그 점들의 패턴을 가장 잘 따라가는 직선이나 곡선을 찾는 것이 피팅이라고 할 수 있습니다. 머신러닝이나 딥러닝에서는 모델이 데이터를 통해 패턴을 학습하면서 실제 데이터와 예측 값의 차이가 최소가 되도록 파라미터를 조정하는데, 이러한 과정 전체를 피팅이라고 합니다.

피팅(Fitting)을 할 때 반드시 1차 함수일 필요는 없습니다. 피팅은 단순히 데이터의 패턴을 잘 설명하도록 어떤 형태의 함수든 데이터를 맞추는 과정을 의미하기 때문에, 문제의 특성에 따라 다양한 형태의 함수를 사용할 수 있습니다. 가장 간단한 예로는 직선 형태의 1차 함수(선형 회귀)를 사용할 수 있지만, 데이터의 패턴이 곡선 형태라면 2차 함수나 3차 함수 같은 다항식 함수를 사용할 수도 있습니다. 또한 더 복잡한 데이터에서는 지수 함수, 로그 함수, 혹은 신경망과 같은 비선형 모델을 사용할 수도 있습니다. 즉, 피팅에서 중요한 것은 함수의 차수가 아니라 데이터의 패턴을 얼마나 잘 설명할 수 있는 모델을 선택하느냐이며, 데이터가 단순하면 1차 함수로도 충분하지만 복잡한 경우에는 더 복잡한 함수나 모델을 사용하는 것이 필요합니다.

Underfitting
Underfitting(언더피팅)은 모델이 데이터의 패턴을 충분히 학습하지 못한 상태를 의미합니다. 즉, 모델이 너무 단순하거나 학습이 충분히 이루어지지 않아 데이터에 존재하는 중요한 관계나 구조를 제대로 반영하지 못하는 경우입니다. 예를 들어 실제 데이터가 곡선 형태의 패턴을 가지고 있는데 이를 직선 같은 단순한 모델로 설명하려 하면 데이터의 전반적인 경향조차 제대로 맞추지 못하게 됩니다. 이 경우 학습 데이터에서도 오차가 크게 나타나며, 모델이 문제의 복잡성을 충분히 표현하지 못해 예측 성능이 전반적으로 낮아지는 특징이 있습니다.
Overfitting
Overfitting(오버피팅)은 모델이 학습 데이터에 너무 과도하게 맞춰진 상태를 의미합니다. 즉, 데이터의 일반적인 패턴뿐 아니라 우연히 포함된 노이즈나 세부적인 변동까지 모두 학습해 버리는 경우입니다. 이렇게 되면 학습 데이터에서는 매우 정확한 예측을 하더라도 새로운 데이터에서는 성능이 크게 떨어질 수 있습니다. 이는 모델이 데이터의 본질적인 규칙을 학습한 것이 아니라 특정 데이터에만 맞는 형태로 지나치게 복잡해졌기 때문이며, 일반화 능력이 떨어지는 것이 주요 특징입니다.
3. 함수 근사에서 "저장" 되는 것
함수 자체에 값을 저장하는 것이 아니라
함수의 파라미터(parameter) 가 학습된다는 것입니다.

강화학습에서 경험을 통해 바뀌는 것은 상태 값이 아니라 함수의 파라미터입니다. 즉, 경험이 함수 안에 저장되는 것입니다.
왜 함수를 사용하면 저장공간이 덜 필요할까?
함수를 사용하는 경우 저장 공간이 덜 필요한 이유는 모든 상태의 값을 직접 저장하는 대신, 그 값들을 계산하는 규칙(함수의 파라미터)만 저장하면 되기 때문입니다. 예를 들어 테이블 방식에서는 상태가 1,000개라면 각 상태의 값을 모두 저장해야 하므로 최소 1,000개의 값을 메모리에 보관해야 합니다. 하지만 함수 근사를 사용하면 상태가 아무리 많아도 값을 직접 저장하지 않고, 상태를 입력하면 값을 계산하는 함수만 있으면 됩니다. 이때 저장되는 것은 함수의 구조와 몇 개의 파라미터(예: 계수나 신경망의 가중치)뿐입니다. 따라서 상태의 수가 매우 많거나 연속적인 경우에도 모든 상태 값을 저장할 필요 없이 소수의 파라미터만으로 다양한 상태의 값을 계산할 수 있기 때문에 저장 공간이 훨씬 적게 필요하게 됩니다.
4. 일반화
강화학습에서 일반화(Generalization)란 에이전트가 학습 과정에서 경험하지 않은 새로운 상태에 대해서도 적절한 가치(Value)나 행동(Action)을 예측할 수 있는 능력을 의미합니다. 테이블 방식에서는 학습한 상태의 값만 저장되기 때문에 처음 보는 상태가 나타나면 그 상태에 대한 정보를 전혀 사용할 수 없습니다. 하지만 함수 근사나 신경망을 사용하면 여러 상태에서 공통적으로 나타나는 패턴을 학습하게 되고, 이 패턴을 기반으로 비슷한 특성을 가진 새로운 상태에서도 합리적인 값을 예측할 수 있습니다. 즉, 일반화란 특정 상태 하나를 기억하는 것이 아니라 여러 상태에서 나타나는 공통적인 관계를 학습하여 비슷한 상황에도 적용할 수 있도록 하는 능력이라고 이해할 수 있으며, 상태 공간이 매우 큰 강화학습 문제에서 매우 중요한 개념입니다.
3. 강화학습에서의 신경망
1. 신경망
강화학습에서 신경망(Neural Network) 은 상태(State)를 입력받아, 그 상태가 얼마나 좋은지에 대한 가치(Value) 나 각 행동(Action)의 가치(Q-value), 또는 어떤 행동을 해야 할지에 대한 정책(Policy) 을 출력하는 함수 역할을 합니다. 즉, 상태가 너무 많아서 각 상태의 값을 테이블에 직접 저장할 수 없을 때, 신경망이 “상태를 보고 값을 계산해주는 근사 함수” 로 사용됩니다. 쉽게 말하면, 신경망은 강화학습에서 에이전트가 복잡한 상태를 이해하고, 그 상태에서 어떤 선택이 좋은지 판단하도록 도와주는 계산기라고 볼 수 있습니다.
상태(State) → 신경망 → 출력(Output)출력은 문제에 따라 달라집니다.
- 상태 가치 V(s): “현재 상태가 얼마나 좋은 상태인가?”를 숫자로 출력. 현재 상태가 목표에 가까우면 큰 값, 위험한 상태면 작은 값
- 행동 가치 Q(s,a): “이 상태에서 각 행동이 얼마나 좋은가?”를 출력.
- 정책 π(a∣s): “이 상태에서 어떤 행동을 선택할 확률이 높은가?”를 출력. 각 행동의 선택 확률을 출력할 수 있습니다.
즉, 강화학습에서 신경망이 학습한다는 말은
경험을 통해 신경망의 가중치가 바뀌면서
더 좋은 가치 예측이나 행동 예측을 하게 된다는 뜻입니다.
2. 신경망의 학습
강화학습에서는 에이전트가 환경과 상호작용합니다. 흐름은 다음과 같습니다.
상태 s 관찰
→ 신경망으로 행동/가치 계산
→ 행동 a 선택
→ 환경이 다음 상태 s'와 보상 r 반환
→ 이 경험으로 신경망 업데이트경험(state, action, reward, next_state)
을 이용해 신경망이 더 정확한 예측을 하도록 가중치를 수정합니다.
4. 가치 기반(Value-Based Reinforcement Learning)
강화학습에서 가치 기반(Value-Based) 방법이란 에이전트가 어떤 상태나 행동이 얼마나 좋은지를 나타내는 가치(Value) 를 학습하고, 그 가치를 기준으로 가장 좋은 행동을 선택하는 방식의 강화학습 방법입니다. 즉, 에이전트는 직접 행동 규칙을 배우는 것이 아니라 각 행동의 점수(가치)를 계산한 뒤 가장 점수가 높은 행동을 선택하게 됩니다. 쉽게 말해 가치 기반 방법은 “어떤 행동이 가장 좋은 점수를 가지는지 계산하는 방식”이라고 볼 수 있습니다.
1. 가치(Value)란 무엇인가
강화학습에서 가치(Value) 는 어떤 상태나 행동이 미래에 얼마나 많은 보상을 가져올 것인지에 대한 기대값을 의미합니다.
- 가치가 높다 → 좋은 상태 또는 좋은 행동
- 가치가 낮다 → 좋지 않은 상태 또는 행동

이 경우 가장 좋은 행동은 오른쪽 이동입니다. 즉, 에이전트는 가치가 가장 높은 행동을 선택하게 됩니다.
2. 가치 기반 강화학습의 핵심 아이디어
가치 기반 강화학습의 핵심 아이디어는 매우 단순합니다.
현재 상태 확인
↓
각 행동의 가치 계산
↓
가장 큰 가치의 행동 선택
행동의 점수를 계산하고 가장 높은 점수를 선택하는 방식입니다.
3. 행동 가치 함수 Q(s,a)
가치 기반 강화학습에서 가장 중요한 개념은 행동 가치 함수(Q-value) 입니다. 수식으로 표현하면 다음과 같습니다.
Q(s,a)
상태 s에서 행동 a를 선택했을 때 앞으로 얻을 것으로 기대되는 보상
예를 들어 다음과 같은 상황이 있다고 가정합니다.

Q(A, 오른쪽) > Q(A, 왼쪽)이므로 에이전트는 오른쪽 행동을 선택하게 됩니다.
4. 행동 선택 방법
가치 기반 방법에서는 일반적으로 다음 규칙을 사용합니다.

상태 s에서 가능한 행동 중 Q값이 가장 큰 행동을 선택한다.
행동 점수표를 만들고 가장 높은 점수를 선택 하는 방식입니다.
5. 가치 기반 학습 과정
가치 기반 강화학습은 다음과 같은 과정을 반복하면서 학습합니다.
1. 현재 상태 관찰
2. 행동 선택
3. 보상 받음
4. 다음 상태 이동
5. 가치(Q값) 업데이트즉 에이전트는 환경과 계속 상호작용하면서 행동의 가치를 점점 더 정확하게 학습하게 됩니다.
6. 대표적인 가치 기반 알고리즘
Q-Learning
가장 대표적인 가치 기반 알고리즘입니다. 다음 상태의 최대 Q값을 이용해 현재 Q값을 업데이트합니다.
SARSA
현재 정책을 기반으로 학습하는 방법입니다. Q-learning보다 보수적인 학습 방식입니다.
DQN (Deep Q Network)
신경망을 이용하여 Q-value를 근사하는 방법입니다. Atari 게임, 로봇 제어, 복잡한 환경같은 문제에서 사용됩니다.
7. 가치 기반 방법의 장점과 단점
장점
직관적인 방식: 행동의 점수를 계산하고 가장 큰 값을 선택하기 때문에 이해하기 쉽습니다.
구현이 비교적 간단: Q-learning 같은 알고리즘은 비교적 간단하게 구현할 수 있습니다.
많은 연구가 진행된 방법: DQN, Double DQN, Dueling DQN 등 다양한 발전 방법이 있습니다.
단점
행동이 수천 개 이상이면 Q값 계산이 어려워집니다.
5. 강화학습의 정책 기반(Policy-Based Reinforcement Learning)
강화학습에서 정책 기반(Policy-Based) 방법이란 에이전트가 상태를 입력받았을 때 어떤 행동을 선택할지에 대한 정책(Policy)을 직접 학습하는 방법입니다. 즉, 행동의 가치를 계산한 뒤 가장 높은 행동을 선택하는 것이 아니라 각 행동을 선택할 확률을 직접 학습하는 방식입니다. 쉽게 말해 정책 기반 강화학습은 “어떤 행동을 할 것인지 규칙 자체를 학습하는 방법”이라고 이해할 수 있습니다.
1. 정책(Policy)이란 무엇인가
정책(Policy)은 상태가 주어졌을 때 어떤 행동을 선택할 것인지 결정하는 규칙을 의미합니다. 수식으로 표현하면 다음과 같습니다.
π(a∣s)
- s : 현재 상태
- a : 행동
- π(a∣s) : 상태 s에서 행동 a를 선택할 확률
예를 들어 다음과 같은 정책이 있다고 가정해 보겠습니다.

이 경우 에이전트는 70% 확률로 오른쪽 이동을 선택하게 됩니다.
2. 정책 기반 강화학습의 핵심 아이디어
정책 기반 강화학습의 핵심 아이디어는 다음과 같습니다.
상태 → 정책 → 행동 확률 → 행동 선택- 상태를 입력으로 받음
- 정책 함수가 행동 확률을 계산
- 그 확률을 기반으로 행동 선택
3. 정책을 함수로 표현
정책은 보통 함수 형태로 표현됩니다.
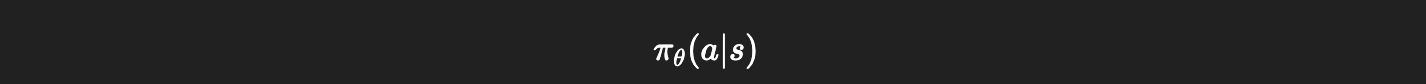
θ : 정책의 파라미터 (신경망 가중치)
state → neural network → action probability위 형태로 표현됩니다. 따라서 신경망이 다음과 같은 출력을 낼 수 있습니다.
[0.1, 0.6, 0.3]
- 행동1 선택 확률 10%
- 행동2 선택 확률 60%
- 행동3 선택 확률 30%
4. 정책 기반 학습 방법
정책 기반 강화학습에서는 좋은 행동의 확률을 높이고 나쁜 행동의 확률을 낮추는 방식으로 학습합니다.
상태 A에서
행동 = 오른쪽
보상 = +10
이 경우 학습은 오른쪽 행동의 확률을 증가합니다.
또한
행동 = 왼쪽
보상 = -5라면 왼쪽 행동의 확률이 감소합니다.
5. 정책 기반 방법이 필요한 이유
행동 공간이 매우 큰 경우
- 로봇 제어
- 드론 제어
행동이 수천 개 이상이면 Q-value 계산이 어렵습니다.
연속 행동 문제
- 자동차 핸들 각도
- 로봇 팔 각도
이 경우 행동이 0.1, 0.2, 0.3 ... 처럼 연속적인 값이 됩니다. 이때는 Q-table 방식이 어렵기 때문에 정책 기반 방법이 사용됩니다.
6. 정책 기반 학습 과정
정책 기반 강화학습의 기본 흐름은 다음과 같습니다.
1. 상태 관찰
2. 정책이 행동 확률 계산
3. 행동 선택
4. 보상 받음
5. 정책 파라미터 업데이트즉 경험을 통해 정책을 계속 수정합니다.
7. 대표적인 정책 기반 알고리즘
정책 기반 강화학습에는 여러 알고리즘이 있습니다. 대표적인 방법은 다음과 같습니다.
Policy Gradient
가장 기본적인 정책 기반 알고리즘입니다. 정책의 파라미터를 직접 업데이트합니다.
REINFORCE
Monte Carlo 기반 정책 학습 방법입니다.
PPO (Proximal Policy Optimization)
현재 가장 많이 사용되는 정책 기반 알고리즘 중 하나입니다.
Actor-Critic
정책과 가치 함수를 동시에 사용하는 방법입니다.
9. 정책 기반 강화학습의 장점과 단점
장점
연속 행동 문제 해결 가능: 로봇 제어 같은 문제에 적합합니다.
확률적 정책 사용 가능: 탐험(exploration)에 유리합니다.
복잡한 행동 공간 처리 가능: 행동이 매우 많은 문제에서도 적용 가능합니다.
단점
학습이 불안정할 수 있음: 정책 업데이트가 너무 크면 학습이 흔들릴 수 있습니다.
샘플 효율이 낮을 수 있음: 많은 경험 데이터가 필요할 수 있습니다.
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.fc1 = nn.Linear(1, 128)
self.fc2 = nn.Linear(128, 128)
self.fc3 = nn.Linear(128, 128)
self.fc4 = nn.Linear(128, 1, bias=False)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = F.relu(self.fc3(x))
x = self.fc4(x)
return x
def true_fun(X):
noise = np.random.rand(X.shape[0]) * 0.4 - 0.2
return np.cos(1.5 * np.pi * X) + X + noise
def plot_results(model):
x = np.linspace(0, 5, 100)
input_x = torch.from_numpy(x).float().unsqueeze(1)
plt.plot(x, true_fun(x), label="Truth")
plt.plot(x, model(input_x).detach().numpy(), label="Prediction")
plt.legend(loc='lower right',fontsize=15)
plt.xlim((0, 5))
plt.ylim((-1, 5))
plt.grid()
def main():
data_x = np.random.rand(10000) * 5 # 0~5 사이 숫자 1만개를 샘플링하여 인풋으로 사용
model = Model()
optimizer = optim.Adam(model.parameters(), lr=0.001)
for step in range(10000):
batch_x = np.random.choice(data_x, 32) # 랜덤하게 뽑힌 32개의 데이터로 mini-batch를 구성
batch_x_tensor = torch.from_numpy(batch_x).float().unsqueeze(1)
pred = model(batch_x_tensor)
batch_y = true_fun(batch_x)
truth = torch.from_numpy(batch_y).float().unsqueeze(1)
loss = F.mse_loss(pred, truth) # 손실 함수인 MSE를 계산하는 부분
optimizer.zero_grad()
loss.mean().backward() # 역전파를 통한 그라디언트 계산이 일어나는 부분
optimizer.step() # 실제로 파라미터를 업데이트 하는 부분
plot_results(model)
if __name__ == '__main__':
main()
반응형
'인공지능 > 강화학습' 카테고리의 다른 글
| Policy 기반 에이전트 (0) | 2026.03.12 |
|---|---|
| Q-learning (0) | 2026.03.11 |
| TD Learning (0) | 2026.03.10 |
| Monte Carlo Learning (0) | 2026.03.09 |
| 벨만기대방정식 (0) | 2026.03.05 |




