고정 헤더 영역
상세 컨텐츠
본문
반응형
1. 컴퓨터 비전
컴퓨터 비전은 인공지능(AI)의 한 분야로, 컴퓨터가 인간처럼 이미지나 영상을 이해하고 분석할 수 있도록 하는 기술입니다. 이는 객체 검출, 이미지 분류, 얼굴 인식, 장면 이해 등 다양한 작업을 포함하며, 주로 머신러닝과 딥러닝을 활용하여 이미지 속 특징을 추출하고 패턴을 학습합니다. 예를 들어, 자율주행 자동차는 컴퓨터 비전을 사용하여 도로의 차선, 보행자, 신호등을 인식하며, 의료 영상 분석에서는 CT나 MRI 이미지를 분석하여 질병을 진단할 수 있습니다. 최근에는 합성곱 신경망(CNN)과 같은 딥러닝 모델이 발전하면서 컴퓨터 비전의 성능이 크게 향상되었으며, 다양한 산업에서 활발히 활용되고 있습니다.
2. 컴퓨터 비전에서의 프레임워크
컴퓨터 비전에서 주로 사용하는 프레임워크로는 OpenCV, TensorFlow, PyTorch 등이 있습니다. OpenCV는 이미지 처리 및 컴퓨터 비전 작업을 위한 오픈소스 라이브러리로, 빠른 속도와 다양한 기능을 제공하여 전처리 및 간단한 비전 작업에 많이 활용됩니다. TensorFlow와 PyTorch는 딥러닝 기반의 컴퓨터 비전 모델을 학습시키는 데 사용되는 대표적인 프레임워크로, 합성곱 신경망(CNN), 객체 검출, 이미지 분할 등의 작업을 쉽게 구현할 수 있도록 지원합니다. TensorFlow는 Google에서 개발한 프레임워크로 대규모 배포와 성능 최적화에 강점을 가지며, PyTorch는 직관적인 코드 작성과 디버깅이 용이하여 연구 및 실험에서 많이 사용됩니다.

3. 컴퓨터 비전에서의 데이터셋
컴퓨터 비전에서 데이터셋은 모델의 성능을 결정하는 가장 중요한 요소 중 하나입니다. 딥러닝 모델은 대량의 이미지 데이터를 학습하여 패턴을 인식하고 일반화하는 능력을 갖추기 때문에, 양질의 데이터셋이 필수적입니다. 데이터셋이 다양하고 균형 잡혀 있을수록 모델은 과적합을 피하고 실제 환경에서도 잘 작동할 가능성이 높아집니다. 예를 들어, ImageNet, COCO, Pascal VOC 같은 대규모 데이터셋은 객체 분류 및 검출 모델 학습에 널리 사용되며, MNIST, CIFAR-10, Fashion-MNIST 등은 기초적인 이미지 분류 실험에 활용됩니다. 또한, 특정 도메인에 특화된 의료 영상 데이터셋이나 자율주행용 데이터셋도 존재하며, 실제 애플리케이션에서 중요한 역할을 합니다. 좋은 데이터셋을 구축하기 위해서는 이미지의 품질, 다양한 환경에서의 데이터 확보, 라벨링의 정확성 등이 중요하며, 최근에는 데이터 증강(Augmentation)과 생성 모델(GANs)을 활용하여 부족한 데이터를 보완하는 기법도 활용되고 있습니다.
1. AI Hub
AI Hub는 한국의 인공지능 데이터 및 알고리즘 공유 플랫폼으로, AI 연구 개발을 지원하기 위해 다양한 데이터셋, 학습용 API, 개발 도구 등을 제공합니다. 한국지능정보사회진흥원(NIA)이 운영하며, 자연어 처리, 컴퓨터 비전, 음성 인식, 자율주행 등 다양한 AI 분야에서 활용할 수 있는 국내 특화 데이터셋을 제공하는 것이 특징입니다. 연구자 및 개발자는 AI Hub에서 공개된 데이터를 활용하여 AI 모델을 학습시키거나 성능을 평가할 수 있으며, 일부 데이터는 직접 다운로드하여 사용할 수도 있습니다. 또한, AI 알고리즘 개발 지원, AI 윤리 가이드라인, AI 관련 교육 자료 등도 제공하여 AI 생태계 활성화에 기여하고 있습니다. 특히, 한국어 기반의 데이터가 많아 한국어 AI 모델 개발에 매우 유용한 플랫폼입니다.
2.COCO
COCO(Common Objects in Context) 데이터셋은 컴퓨터 비전 분야에서 객체 검출(Object Detection), 이미지 분할(Image Segmentation), 이미지 캡셔닝(Image Captioning) 등의 연구를 위해 널리 사용되는 대규모 데이터셋입니다. Microsoft에서 개발한 이 데이터셋은 일상적인 장면에서 촬영된 다양한 객체가 포함된 이미지들로 구성되어 있으며, 약 33만 개의 이미지와 150만 개 이상의 객체 주석(Annotation)이 포함되어 있습니다. COCO 데이터셋의 특징은 정밀한 객체 경계 정보(폴리곤 기반 Segmentation), 다중 객체 포함 이미지, 풍부한 주석 정보(객체 클래스, 키포인트, 캡션 등)입니다. 이러한 특성 덕분에 COCO는 딥러닝 기반의 객체 검출, 세그멘테이션, 인스턴스 검출, 행동 인식 등의 연구에 필수적인 데이터셋으로 자리 잡았으며, 매년 COCO 챌린지를 통해 최신 AI 모델들의 성능을 평가하는 데 사용되고 있습니다.
3. Open Images Dataset
Open Images Dataset은 Google이 제공하는 대규모 컴퓨터 비전 데이터셋으로, 객체 검출(Object Detection), 이미지 분류(Image Classification), 이미지 세그멘테이션(Image Segmentation) 등의 연구를 위해 설계되었습니다. Open Images 데이터셋은 900만 개 이상의 이미지와 6억 개 이상의 바운딩 박스 주석(Bounding Box Annotation)을 포함하며, 약 600개의 객체 클래스(Label)를 제공합니다. COCO나 Pascal VOC보다 훨씬 많은 객체 수와 방대한 데이터 양을 제공하여 딥러닝 모델의 학습 및 일반화 성능을 높이는 데 유용합니다. 또한, 이미지에는 객체 검출을 위한 바운딩 박스뿐만 아니라 관계 주석(Visual Relationship), 행동 태그(Action Tagging), 랜드마크 정보 등이 포함되어 있어, 다양한 컴퓨터 비전 연구에 활용할 수 있습니다. Open Images는 실제 웹에서 수집된 이미지들로 구성되어 있으며, 보다 현실적인 데이터로 AI 모델을 학습시키는 데 유리한 데이터셋입니다.
4. KITTI
KITTI 데이터셋은 자율주행 및 컴퓨터 비전 연구를 위한 대표적인 대규모 데이터셋으로, 독일 카를스루에 공과대학교(KIT)와 토요타 기술연구소(Toyota Technological Institute)에서 개발하였습니다. 이 데이터셋은 실제 도로 환경에서 촬영된 고해상도 영상과 다양한 센서 데이터를 포함하며, 특히 LiDAR(라이다) 포인트 클라우드, 스테레오 영상, GPS/IMU 데이터를 함께 제공하는 것이 특징입니다. KITTI는 객체 검출(Object Detection), 주행 경로 예측, 깊이 추정(Depth Estimation), SLAM(동시적 위치 추정 및 지도 작성) 등 다양한 연구에 활용되며, 자율주행 AI 및 로보틱스 연구에서 필수적인 벤치마크 데이터셋으로 자리 잡고 있습니다. 또한, 다양한 주행 시나리오(도심, 교외, 고속도로 등)를 포함하여 실제 환경에서의 AI 모델 성능을 평가하는 데 매우 유용합니다.
4. 어노테이션
어노테이션(Annotation)은 머신러닝, 특히 지도학습(Supervised Learning)에서 데이터에 대한 정답(라벨)을 부여하는 과정을 의미합니다. 컴퓨터 비전에서는 이미지나 영상 내 객체의 위치, 크기, 카테고리 등을 사람이 직접 지정하거나 자동화된 도구를 이용해 태그하는 작업을 포함합니다. 대표적인 어노테이션 유형으로는 바운딩 박스(Bounding Box) 어노테이션(객체의 위치를 사각형으로 표시), 폴리곤 어노테이션(정확한 윤곽선 표시), 세그멘테이션(Segmentation)(픽셀 단위의 라벨링), 키포인트(Keypoint) 어노테이션(얼굴, 손, 관절 등의 특징점 표시) 등이 있습니다. 이러한 어노테이션 데이터는 딥러닝 모델이 객체를 학습하고 인식하는 데 필수적이며, 데이터 품질이 모델 성능에 직접적인 영향을 미칩니다. 최근에는 자동 어노테이션 도구나 크라우드소싱 플랫폼을 활용하여 대량의 데이터를 효율적으로 라벨링하는 기술도 발전하고 있습니다. 참고
- 바운딩 박스(Bounding Box)
- 객체를 감싸는 사각형 형태의 어노테이션으로, 객체 검출(Object Detection)에서 가장 널리 사용됨.
- 예: COCO, PASCAL VOC 데이터셋.

- 폴리곤(Polygon) 어노테이션
- 불규칙한 형태의 객체를 더 정확하게 표현하기 위해 다각형 형태로 라벨링하는 방식.
- 예: 자율주행 차량의 도로 표지판, 건물 경계선 표시.

- 세그멘테이션(Segmentation)
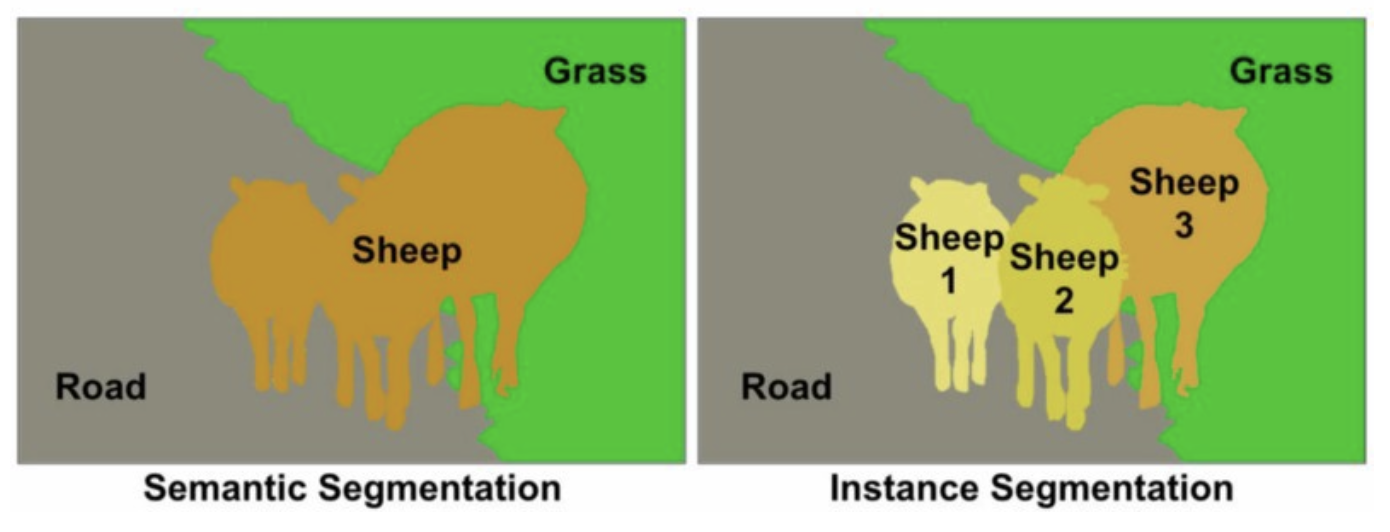
- 픽셀 단위로 객체를 구분하는 방법으로, 인스턴스 세그멘테이션(Instance Segmentation)과 의미론적 세그멘테이션(Semantic Segmentation)으로 나뉨.
- 예: COCO, ADE20K 데이터셋.
- 키포인트(Keypoint) 어노테이션
- 얼굴 인식, 동작 분석 등에 사용되며, 눈, 코, 손목, 팔꿈치 등 특정 지점에 점을 찍어 라벨링.
- 예: OpenPose, COCO Keypoints 데이터셋.

- 스켈레톤(Skeleton) 어노테이션
- 여러 개의 키포인트를 선으로 연결하여 인체의 구조나 포즈를 표현하는 방식.
- 예: 행동 인식, 스포츠 분석.

- 라인(Line) 및 폴리라인(Polyline) 어노테이션
- 도로 차선, 경계선 등을 라인 형태로 라벨링하는 방식.
- 예: 자율주행에서 도로 차선 감지.

- 3D 바운딩 박스(3D Bounding Box)
- 객체의 길이, 너비, 높이 정보를 포함하여 3차원 공간에서 라벨링하는 방법.
- 예: LiDAR 데이터(자율주행).

5. 컴퓨터 비전의 대표 TASK

반응형
'인공지능 > 컴퓨터 비전' 카테고리의 다른 글
| 이안류 CCTV 데이터셋 (0) | 2025.03.06 |
|---|---|
| Object Detection (0) | 2025.02.25 |
| OCR (0) | 2025.02.20 |
| OpenCV (0) | 2025.02.18 |
| 포켓몬 분류 데이터셋 (0) | 2025.02.17 |




