고정 헤더 영역
상세 컨텐츠
본문
반응형
1. Object Detection
Object Detection(객체 탐지)은 이미지나 영상에서 특정 객체의 존재 여부를 확인하고, 해당 객체의 위치를 바운딩 박스(bounding box)로 표시하는 기술입니다. 이는 컴퓨터 비전에서 중요한 분야로, 이미지 내에서 여러 개의 객체를 동시에 탐지하고 분류할 수 있습니다. Object Detection은 주로 딥러닝 기반의 CNN(합성곱 신경망) 모델을 활용하며, 대표적인 알고리즘으로는 R-CNN 계열(Faster R-CNN, Mask R-CNN), YOLO(You Only Look Once), SSD(Single Shot MultiBox Detector) 등이 있습니다. 이러한 기술은 자율 주행, 보안 감시, 의료 영상 분석, 증강 현실 등 다양한 분야에서 활용됩니다.
Object Detection 논문 추천 리스트

2. 객체 탐지 전통적인 기법
객체 탐지(Object Detection)에서 전통적인 기법이란 딥러닝이 등장하기 이전에 사용되던 방식으로, 핸드크래프트된 특징 추출과 기계학습 분류기를 결합한 방법을 말합니다. 대표적으로 HOG(Histogram of Oriented Gradients), SIFT(Scale-Invariant Feature Transform) 같은 특징 추출기를 통해 이미지에서 경계·패턴을 뽑아내고, 이를 SVM(Support Vector Machine)이나 Adaboost 같은 분류기에 입력하여 객체 여부를 판별했습니다. 또한, 탐지 과정에서는 윈도우 슬라이딩 기법이나 선택적 탐색(Selective Search) 같은 방법을 이용해 후보 영역을 만들어냈습니다. 이 방식은 당시 좋은 성과를 냈지만, 특징을 직접 설계해야 하고 복잡한 배경이나 다양한 스케일 변화에 약하다는 한계가 있어 이후 딥러닝 기반 객체 탐지로 빠르게 대체되었습니다.
1. 특징 추출 (Feature Extraction)
- 핸드크래프트 특징이라고 불리며, 사람이 규칙을 설계해서 이미지를 수치로 바꿉니다.
- HOG (Histogram of Oriented Gradients) → 이미지의 밝기 변화(경계선, 윤곽선)를 방향 히스토그램으로 표현
- SIFT (Scale-Invariant Feature Transform) → 크기나 회전에 변해도 동일하게 잡히는 특징점 검출
- SURF, LBP 등도 사용됨
👉 이 과정을 통해 “이 이미지는 경계선이 많네, 둥근 패턴이 있네” 같은 수치화된 특징 벡터를 얻습니다.
2. 분류기 학습 (Classifier Training)
- 추출된 특징 벡터를 머신러닝 모델에 넣어 객체인지 아닌지를 판별합니다.
- SVM (Support Vector Machine), Adaboost, 랜덤 포레스트 등
- 예: 얼굴 탐지 → 얼굴 특징(HOG) 추출 → SVM이 “얼굴이다/아니다” 판별
3. 후보 영역 탐색 (Region Proposal)
- 이미지를 그냥 한 번에 다 보는 게 아니라, 객체가 있을 법한 위치를 찾아내는 과정이 필요했습니다.
- 슬라이딩 윈도우(Sliding Window): 이미지를 작은 창(window)으로 조금씩 옮겨가며 탐색
- 선택적 탐색(Selective Search): 색·질감·경계선 등을 기준으로 객체 후보 영역 생성

3. 객체 탐지 딥러닝 기반 기법
객체 탐지의 딥러닝 기반 기법은 크게 1단계 탐지(One-Stage)와 2단계 탐지(Two-Stage)로 나눌 수 있습니다. 1단계 탐지는 입력 이미지를 한 번에 처리해 위치와 클래스를 동시에 예측하는 방식으로, YOLO·SSD·RetinaNet 등이 대표적이며 속도가 매우 빨라 실시간 응용에 적합하지만 작은 객체나 복잡한 배경에서 정확도가 다소 떨어질 수 있습니다. 반면 2단계 탐지는 먼저 후보 영역(Region Proposal)을 제안한 뒤, 그 영역을 다시 정밀하게 분류하고 박스를 보정하는 방식으로, R-CNN 계열(Faster R-CNN, Mask R-CNN 등)이 대표적입니다. 이 방식은 정확도가 높고 작은 객체에도 강하지만 속도가 느려 실시간 적용에는 불리합니다.
1. 1단계 탐지(One-Stage Detection)
1단계 탐지 기법은 객체 위치 추정과 클래스 분류를 한 번에 동시에 수행하는 방식입니다. 즉, 입력 이미지를 바로 격자(grid)나 앵커 박스(anchor box) 단위로 나누고, 각 영역에서 객체의 존재 여부와 클래스, 위치 좌표를 곧바로 예측합니다. 대표적인 알고리즘으로는 YOLO(You Only Look Once), SSD(Single Shot MultiBox Detector), RetinaNet 등이 있으며, 속도가 빠르고 실시간 처리에 유리하지만, 작은 객체나 복잡한 배경에 대해서는 상대적으로 정확도가 떨어질 수 있습니다.
- 예측 방식
- Anchor-based: “여러 크기의 집 모형(앵커)을 준비해두고 → 조금씩 맞춰간다.”
- Anchor-free: “그 자리에서 바로 집 위치와 크기를 예측한다.”
- 학습 방식: 모델이 답을 내면, 선생님(손실 함수)이 “클래스는 맞췄나? 박스 위치는 얼마나 차이나나?” 채점 → 점수에 따라 모델이 조금씩 고쳐 나가면서 학습된다.
2. 2단계 탐지(Two-Stage Detection)
2단계 탐지 기법은 먼저 객체가 있을 법한 후보 영역(region proposal)을 찾고, 그 영역을 다시 분류·정교화하는 방식입니다. 즉, 1단계에서 "여기 객체가 있을 수 있다"라는 후보 박스를 만들고, 2단계에서 그 후보를 세밀하게 분석해 최종 클래스와 위치를 결정합니다. 대표적인 알고리즘은 R-CNN 계열(R-CNN, Fast R-CNN, Faster R-CNN, Mask R-CNN)이며, 정확도가 높고 작은 객체 탐지에도 강하지만, 속도가 느려 실시간 처리에는 덜 적합합니다.
- 1단계 학습: 후보 영역을 얼마나 잘 잡는지 → “진짜 물체 근처를 놓치지 않고 잡아냈는가?”
- 2단계 학습: 후보 영역 안에서 “정답 클래스와 좌표를 얼마나 정확히 맞췄는가?”
- 손실 함수가 각각 채점하고, 모델은 두 단계를 통해 점점 더 똑똑해집니다.

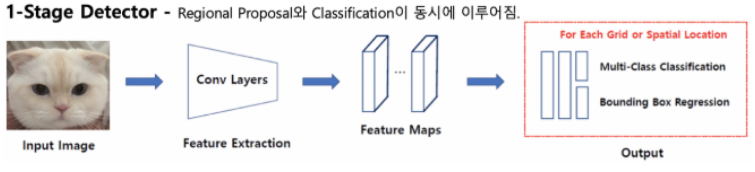
4. YOLO
YOLO(You Only Look Once)는 이미지를 격자 단위로 나누어 각 격자에서 객체의 위치(바운딩 박스 좌표)와 클래스를 동시에 예측하는 1단계 객체 탐지(One-Stage Detection) 알고리즘입니다. 한 번의 신경망 추론으로 전체 이미지의 탐지를 수행하기 때문에 매우 빠르고, 실시간 객체 탐지에 적합하다는 장점이 있습니다. YOLO 계열은 v1에서 시작해 v3까지는 Joseph Redmon이 개발했으며, 이후 v4·v7은 커뮤니티 연구자들, v5·v8·v11은 Ultralytics가 주도적으로 발전시켜 현재까지 이어지고 있습니다. 이러한 발전 과정을 거치면서 YOLO는 속도와 정확도의 균형을 잡은 대표적인 객체 탐지 모델로 자리 잡아 다양한 산업 현장에서 활용되고 있습니다.
1. YOLO 모델 크기별 분류
- n (nano): 초경량 모델로 모바일 및 임베디드 장치에서 사용하기 적합합니다.
- s (small): 속도가 빠르면서도 정확도가 준수하여 실시간 추론이 필요한 경우 사용합니다.
- m (medium): 균형 잡힌 모델로 중간 정도의 성능과 속도를 제공합니다.
- l (large): 높은 정확도를 요구하는 애플리케이션에서 사용합니다.
- x (extra-large): 최대 성능을 발휘하지만, 속도가 상대적으로 느립니다.
2. YOLO 모델 유형별 분류
- YOLO Detect: 가장 일반적인 객체 탐지 모델로, 특정 객체의 위치와 크기를 바운딩 박스로 반환합니다.
- YOLO Segment: 객체 탐지뿐만 아니라 픽셀 단위의 분할(Segmentation)까지 수행하는 모델입니다.
- YOLO Pose: 사람의 관절 위치를 탐지하여 포즈를 예측하는 모델입니다.
- YOLO Cls: 이미지를 분류하는 모델입니다.
- YOLO OBB: 이미지를 회전하여 객체를 탐지하는 모델입니다.
5. PascalVOC 2007
PascalVOC 2007은 객체 탐지(Object Detection), 분할(Segmentation), 동작 인식(Action Recognition) 등의 다양한 컴퓨터 비전 과제를 위한 벤치마크 데이터셋입니다. 총 20개의 객체 클래스(예: 사람, 자동차, 개, 고양이 등)를 포함하며, 훈련(train), 검증(val), 테스트(test) 세트로 구성되어 있습니다. 각 이미지에는 객체의 경계 상자(Bounding Box) 및 해당 클래스 레이블이 주어지며, Mean Average Precision(mAP) 평가 기준을 적용하여 성능을 측정합니다.
from pathlib import Path
root = Path('./pascal_datasets')
Path('./pascal_datasets/trainval').mkdir(parents=True, exist_ok=True)
Path('./pascal_datasets/test').mkdir(parents=True, exist_ok=True)
for path1 in ('images', 'labels'):
for path2 in ('train2007', 'val2007', 'test2007'):
new_path = root / 'VOC' / path1 / path2
new_path.mkdir(parents=True, exist_ok=True)# PascalVOC 2007 Train/Val
# train: 2501장, val: 2510장
%cd /content/pascal_datasets/trainval
!unzip -q VOCtrainval_06-Nov-2007.zip
# test: 4952장
%cd /content/pascal_datasets/test
!unzip -q VOCtest_06-Nov-2007.zip
# 어노테이션을 YOLO 형식으로 변환
!git clone https://github.com/ssaru/convert2Yolo.git
%cd convert2Yolo/
%pip install -qr requirements.txt
# datasets: 데이터셋이 VOC 형식임을 지정
# img_path: 이미지 파일 경로
# label: 어노테이션(xml) 경로
# convert_output_path: YOLO 형식으로 변환된 라벨 저장 경로
# img_type: 사용할 이미지 파일 확장자
# manifest_path: 변환 과정에서 사용할 추가적인 정보 파일 저장 경로
# cls_list_file: VOC에서 사용할 클래스 목록이 정의된 파일
!python example.py \
--datasets VOC \
--img_path /content/pascal_datasets/trainval/VOCdevkit/VOC2007/JPEGImages \
--label /content/pascal_datasets/trainval/VOCdevkit/VOC2007/Annotations \
--convert_output_path /content/pascal_datasets/VOC/labels/train2007 \
--img_type '.jpg' \
--manifest_path /content/pascal_datasets \
--cls_list_file ./voc.names
!python example.py \
--datasets VOC \
--img_path /content/pascal_datasets/test/VOCdevkit/VOC2007/JPEGImages \
--label /content/pascal_datasets/test/VOCdevkit/VOC2007/Annotations \
--convert_output_path /content/pascal_datasets/VOC/labels/test2007 \
--img_type '.jpg' \
--manifest_path /content/pascal_datasets \
--cls_list_file ./voc.names
# /content/pascal_datasets/trainval/VOCdevkit/VOC2007/ImageSets/Main/val.txt 파일을 읽어서
# /content/pascal_datasets/VOC/labels/train2007 파일 중 txt 문서에 있는 파일을
# /content/pascal_datasets/VOC/labels/val2007 으로 옮기기
import shutil
path = '/content/pascal_datasets/trainval/VOCdevkit/VOC2007/ImageSets/Main/val.txt'
with open(path) as f:
image_ids = f.read().strip().split()
for id in image_ids:
ori_path = '/content/pascal_datasets/VOC/labels/train2007'
mv_path = '/content/pascal_datasets/VOC/labels/val2007'
shutil.move(f'{ori_path}/{id}.txt', f'{mv_path}/{id}.txt')
# /content/pascal_datasets/trainval/VOCdevkit/VOC2007/JPEGImages 와
# /content/pascal_datasets/test/VOCdevkit/VOC2007/JPEGImages 에서
# 이미지를 가져와 디렉토리에 맞게 저장
import os
path = '/content/pascal_datasets'
for folder, subset in ('trainval', 'train2007'), ('trainval', 'val2007'), ('test', 'test2007'):
ex_imgs_path = f'{path}/{folder}/VOCdevkit/VOC2007/JPEGImages'
label_path = f'{path}/VOC/labels/{subset}'
img_path = f'{path}/VOC/images/{subset}'
print(subset, ": ", len(os.listdir(label_path)))
for lbs_list in os.listdir(label_path):
shutil.move(os.path.join(ex_imgs_path, lbs_list.split('.')[0]+'.jpg'),
os.path.join(img_path, lbs_list.split('.')[0]+'.jpg'))
%cd /content/
6. YAML 파일
YAML 파일은 모델 구성, 데이터 경로, 하이퍼파라미터 등을 정의하는 설정 파일로, 모델 학습과 추론을 자동화하는 데 중요한 역할을 합니다. 주로 data.yaml과 model.yaml 같은 파일이 있으며, data.yaml은 학습 및 검증 데이터셋의 경로, 클래스 개수, 클래스 이름 등을 정의하고, model.yaml은 네트워크 구조(레이어, 채널 수, 활성화 함수 등)를 설정합니다. YAML 형식은 가독성이 뛰어나고 계층적 구조를 쉽게 표현할 수 있어 YOLO의 설정을 직관적으로 관리할 수 있으며, 이를 통해 사용자 맞춤형 모델을 효율적으로 구축할 수 있습니다.
아래 내용을 custom_voc.yaml로 저장합니다.
path: /content/pascal_datasets/VOC
train:
- images/train2007
val:
- images/val2007
test:
- images/test2007
nc: 20
names: ['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog',
'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor']
!pip install ultralytics
from ultralytics import YOLO
# data: 데이터셋 설정 파일
# epochs: 학습 에포크 수
# batch: 배치 크기
# imgsz: 입력 이미지 크기
# device: GPU(0), CPU(-1)
# workers: 데이터 로딩에 사용할 CPU 스레드 수
# name: 학습 결과 저장 폴더명
model = YOLO('yolov8s.pt')
results = model.train(
data='custom_voc.yaml',
epochs=10,
batch=32,
imgsz=640,
device=0,
workers=2,
name='custom_s'
)
7. 객체 탐지 모델의 성능 평가 지표
정밀도(Precision)
객체 탐지 모델이 예측한 객체 중 실제로 정답인 객체의 비율을 의미합니다. 즉, 모델이 "이것이 객체다"라고 판단한 것들 중에서 실제로 맞는 것이 얼마나 많은지를 측정합니다. 수식으로 표현하면 Precision = (TP) / (TP + FP)이며, 여기서 TP(True Positive)는 모델이 올바르게 탐지한 객체 수, FP(False Positive)는 잘못 탐지한 객체 수를 뜻합니다. 정밀도가 높을수록 모델이 잘못된 탐지를 덜 한다는 의미입니다.
재현율(Recall)
실제 존재하는 객체 중에서 모델이 올바르게 탐지한 객체의 비율을 의미합니다. 즉, 놓치지 않고 얼마나 많은 객체를 찾았는지를 평가합니다. 수식으로 표현하면 Recall = (TP) / (TP + FN)이며, 여기서 FN(False Negative)은 모델이 놓친 실제 객체 수를 의미합니다. 재현율이 높을수록 모델이 더 많은 객체를 탐지하지만, 때때로 잘못된 탐지(FP)도 많아질 수 있습니다.
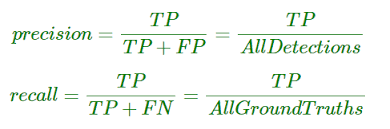
AP(Average Precision)
특정 클래스에 대해 Precision-Recall 곡선을 기반으로 평균 정밀도를 계산한 값입니다. AP는 Recall을 0에서 1까지 변화시키면서 Precision을 계산한 후 평균을 내는 방식으로 구합니다. 객체 탐지 모델의 성능을 측정하는 대표적인 방법이며, 보통 특정 IoU 기준에서 계산됩니다(예: AP@IoU=0.5는 IoU가 0.5 이상인 경우에 대해 AP를 구함)

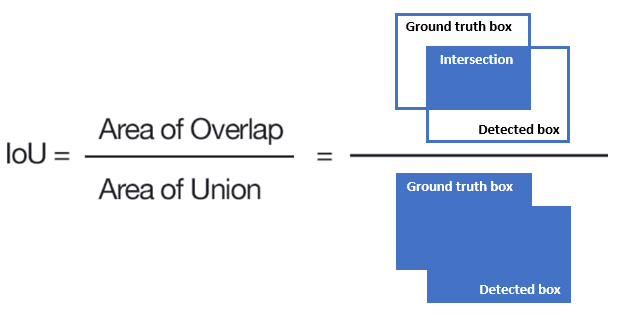
IoU(Intersection over Union)
예측된 바운딩 박스와 실제 객체의 바운딩 박스가 얼마나 겹치는지를 나타내는 값입니다. IoU는 두 박스가 겹치는 영역의 면적을 두 박스의 총 합집합 면적으로 나누어 계산합니다. 값이 1에 가까울수록 예측 박스와 실제 박스가 거의 일치한다는 뜻이며, 보통 객체 탐지 성능 평가에서 특정 임계값(예: IoU ≥ 0.5)을 기준으로 모델의 정확도를 평가합니다.
mAP(mean Average Precision)
여러 클래스에 대한 AP 값을 평균 낸 값으로, 전체 모델의 객체 탐지 성능을 평가하는 종합적인 지표입니다. 단일 클래스가 아닌 전체 데이터셋에 포함된 모든 클래스의 성능을 반영하며, 다양한 IoU 임곗값(예: 0.5~0.95)에 대해 평균을 내기도 합니다. 높은 mAP 값은 모델이 다양한 클래스의 객체를 정확하게 탐지한다는 것을 의미합니다.
mAP@50
IoU(Intersection over Union)가 0.5(50%) 이상이면 정답으로 인정하고 계산한 평균 정밀도입니다. 즉, 모델이 대략적인 위치라도 맞추면 성능이 좋게 나옵니다.
mAP@50-95
IoU를 0.5부터 0.95까지 0.05 간격으로 변화시키면서 성능을 평가한 평균 정밀도입니다. 즉, 객체의 위치를 더욱 정확하게 맞춰야 높은 점수를 받기 때문에 더 엄격한 기준입니다.
FPS
초당 몇 개의 이미지를 처리할 수 있는지를 의미하며, 값이 높을수록 모델이 빠르게 동작한다는 뜻입니다. 예를 들어 30 FPS라면 1초에 30장의 이미지를 처리할 수 있다는 의미입니다.
Latency
한 장의 이미지를 입력했을 때 결과가 나오기까지 걸리는 시간으로, 보통 밀리초(ms) 단위로 측정합니다. 예를 들어 Latency가 50ms라면, 한 장의 이미지를 탐지하는 데 0.05초가 걸린다는 뜻입니다.
# 학습된 모델 로드
model = YOLO("runs/detect/custom_s/weights/best.pt")
# 검증 수행
results = model.val(
data="custom_voc.yaml", # 데이터셋 설정
imgsz=640, # 이미지 크기
iou=0.5, # IoU 임계값
batch=32, # 배치 크기
device=0, # GPU 사용
workers=2, # 데이터 로드 시 병렬 처리할 워커 수
half=True, # FP16 연산 활성화 (속도 향상)
split="test" # 테스트 데이터셋을 사용
)
print(results)
model = YOLO("runs/detect/custom_s/weights/best.pt")
# 객체 탐지 수행
results = model.predict(
source="/content/pascal_datasets/VOC/images/custom2007", # 테스트 이미지 폴더
imgsz=640, # 입력 이미지 크기
conf=0.25, # 신뢰도(Confidence) 임계값
device=0, # GPU 사용 (CPU 사용 시 "cpu")
save=True, # 탐지 결과 저장
save_txt=True, # 탐지 결과를 txt 형식으로 저장 (YOLO 포맷)
save_conf=True # 탐지된 객체의 신뢰도 점수도 저장
)
print(results)
반응형
'인공지능 > 컴퓨터 비전' 카테고리의 다른 글
| Segmentation (0) | 2025.03.10 |
|---|---|
| 이안류 CCTV 데이터셋 (0) | 2025.03.06 |
| OCR (0) | 2025.02.20 |
| OpenCV (0) | 2025.02.18 |
| 포켓몬 분류 데이터셋 (0) | 2025.02.17 |




