고정 헤더 영역
상세 컨텐츠
본문
반응형
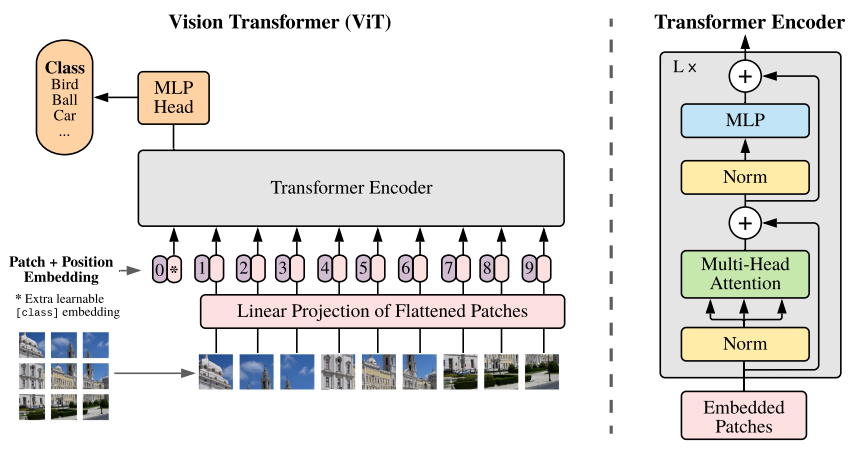
Vision Transformer(ViT)는 이미지 인식 문제를 기존의 CNN 방식이 아니라 Transformer 구조로 직접 해결한 모델입니다. ViT는 이미지를 작은 패치(patch) 단위로 나눈 뒤 이를 토큰(token)처럼 취급하고, 각 패치 간의 관계를 Self-Attention으로 학습함으로써 이미지 전체의 전역적 문맥을 효과적으로 이해합니다. 이 접근은 국소적인 특징 추출에 강한 CNN과 달리, 멀리 떨어진 영역 간의 상관관계를 한 번에 파악할 수 있다는 장점이 있으며, 충분한 데이터와 함께 학습될 경우 CNN 기반 모델을 능가하는 성능을 보입니다. 결과적으로 ViT는 “이미지를 시퀀스로 바라본다”는 관점 전환을 통해 컴퓨터 비전과 자연어 처리의 경계를 허문 대표적인 모델로 평가받고 있습니다.
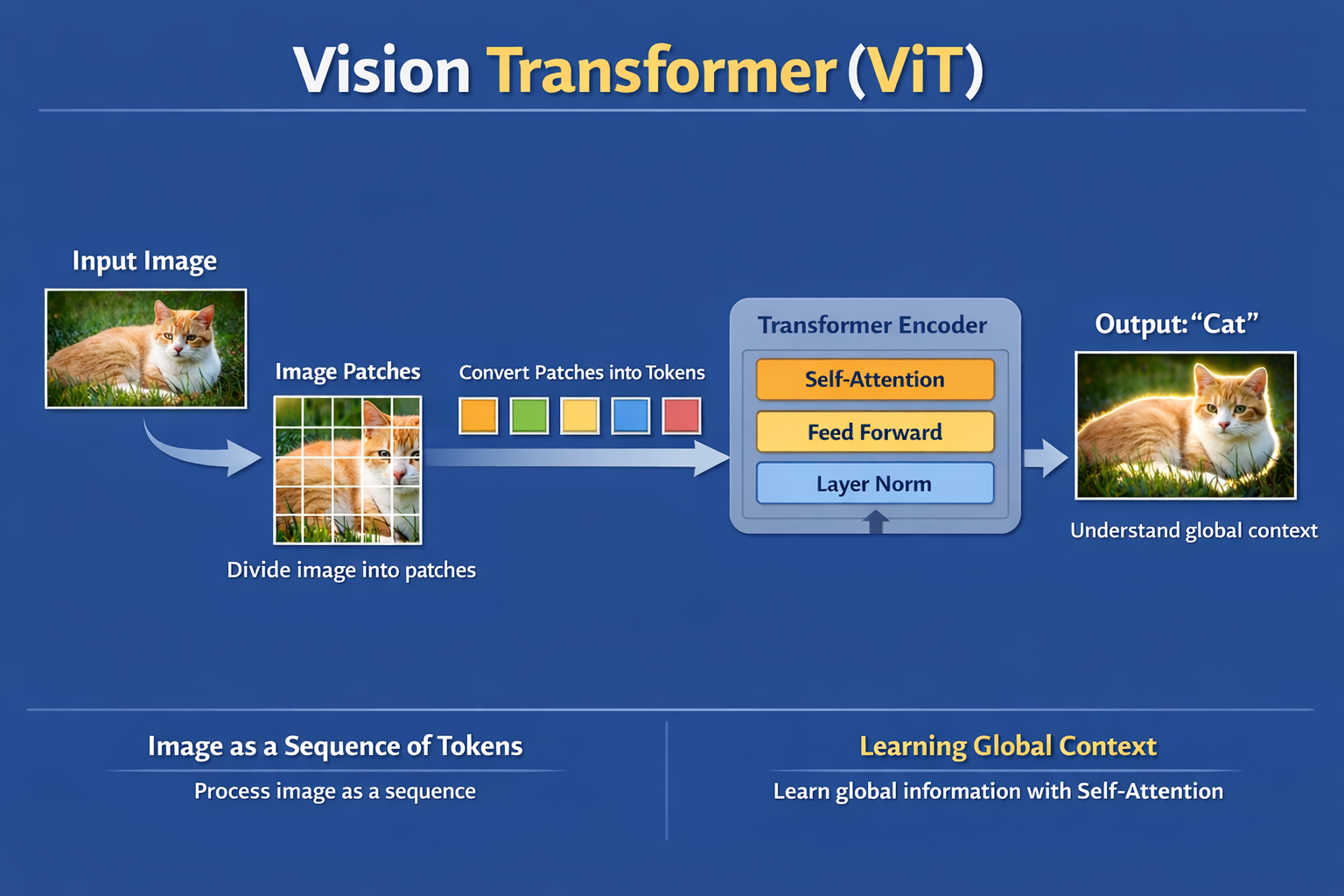
① Input Image
모델에 입력되는 원본 이미지입니다. ViT는 입력 이미지를 그대로 합성곱 연산에 적용하지 않고, 이후 단계에서 일정한 크기의 패치 단위로 분할하여 처리합니다.
② Divide Image into Patches
입력 이미지를 고정 크기의 패치(patch)로 균등하게 분할합니다.
이 과정은 ViT의 핵심 전처리 단계로, 이미지 전체를 패치들의 시퀀스(sequence)로 재구성하기 위한 준비 단계입니다.
③ Image Patches
분할된 각 패치는 이미지의 국소적인 시각 정보(local visual information)를 포함하며, 이후 독립적인 처리 단위로 사용됩니다. 이 시점에서 이미지는 더 이상 하나의 2차원 행렬이 아니라, 여러 개의 패치 집합으로 표현됩니다.
④ Convert Patches into Tokens
각 이미지 패치는 펼침(flatten) 연산을 거친 후 선형 변환을 통해 고정 차원의 벡터(embedding)로 변환됩니다. 이렇게 변환된 벡터는 Transformer에 입력되는 Patch Token이 되며, 이는 자연어 처리에서의 토큰과 동일하게 모델의 기본 입력 단위로 취급됩니다.
⑤ Transformer Encoder
Patch Token 시퀀스는 Transformer Encoder에 입력됩니다.
Encoder 내부에서는
- Self-Attention을 통해 모든 패치 간의 상호 관계를 계산하고
- Feed Forward Network를 통해 특징을 비선형적으로 변환하며
- Residual Connection과 Layer Normalization을 통해 학습 안정성과 정보 보존을 유지합니다.
이 구조는 입력 토큰의 순차 처리 없이 병렬적으로 계산이 이루어진다는 특징을 가집니다.
⑥ Learning Global Context
Self-Attention 메커니즘을 통해 ViT는 이미지 내의 패치 간 관계를 전역적(global)으로 학습합니다. 이로 인해 공간적으로 멀리 떨어진 영역 간의 연관성도 직접적으로 모델링할 수 있으며, 이는 국소 수용 영역에 의존하는 CNN과 구별되는 중요한 특성입니다.
⑦ Output (Classification Result)
Transformer Encoder의 출력은 분류 헤드(classification head)를 거쳐 최종 예측 결과를 생성합니다. 이 결과는 이미지 전체의 패치 정보를 종합적으로 반영한 판단에 기반합니다.
※ Vision Transformer는 이미지를 패치 단위의 시퀀스로 변환한 뒤, Transformer의 Self-Attention 구조를 활용하여 이미지 전역의 관계를 학습하는 비전 모델입니다.
- 트랜스포머 모델이 데이터가 늘어남에 따라 성능의 향상이 기존 CNN모델보다 좋음
- 학습 데이터가 많아질수록 트랜스포머가 CNN의 성능을 능가
- 이미지 크기가 달라짐에 따라, patch를 변경하는 등 유연하게 대응 가능
- 이미지가 커지면 patch 수의 증가로 조절
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
image = np.random.rand(8, 8, 3).astype(np.float32)
image = image.reshape(2, 4, 2, 4, 3)
image = image.transpose(0, 2, 1, 3, 4)
patches = image.reshape(-1, 4, 4, 3)
print("patches:", patches.shape)
patches = torch.tensor(patches)
embedding_dim = 32
num_heads = 4
num_transformer_layers = 2
num_classes = 10
mlp_dim = 256
def patch_embedding(patches, embedding_dim):
N, Ph, Pw, C = patches.shape
patch_dim = Ph * Pw * C
patch_flat = patches.reshape(N, patch_dim)
patch_flat = patch_flat.unsqueeze(0)
proj = nn.Linear(patch_dim, embedding_dim)
tokens = proj(patch_flat)
return tokens, proj
tokens, patch_proj = patch_embedding(patches, embedding_dim)
print("tokens:", tokens.shape)
B, N, D = tokens.shape
cls_token = nn.Parameter(torch.zeros(1, 1, D))
x = torch.cat([cls_token.expand(B, -1, -1), tokens], dim=1)
pos_embed = nn.Parameter(torch.randn(1, x.size(1), D) * 0.02)
x = x + pos_embed
encoder_layer = nn.TransformerEncoderLayer(
d_model=D,
nhead=num_heads,
dim_feedforward=mlp_dim,
batch_first=True
)
transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers=num_transformer_layers)
z = transformer_encoder(x)
classification_layer = nn.Linear(D, num_classes)
logits = classification_layer(z[:, 0, :])
output = F.log_softmax(logits, dim=-1)
pred_class = output.topk(1, dim=-1).indices.item()
print("class :", pred_class)반응형




