고정 헤더 영역
상세 컨텐츠
본문
반응형
1. Flamingo
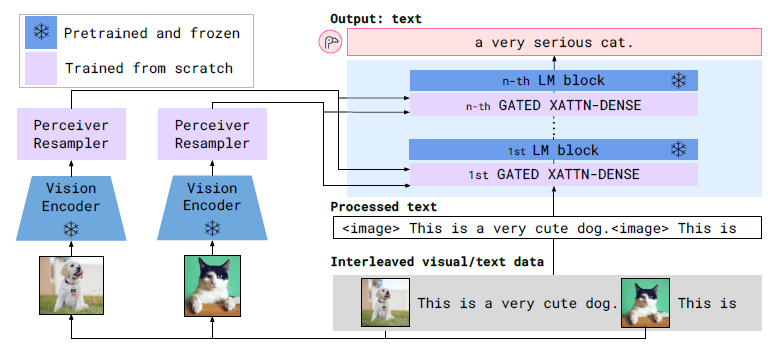
Flamingo는 DeepMind에서 제안한 대규모 멀티모달 모델로, 사전학습된 Vision Encoder와 대형 언어모델(LLM)을 유지한 채, 중간에 Cross-Attention 레이어를 삽입하여 이미지 정보를 텍스트 생성 과정에 주입하는 구조를 사용합니다. 핵심 특징은 여러 장의 이미지와 긴 텍스트를 함께 입력받아 문맥을 유지하면서 Few-shot 방식으로 추론할 수 있다는 점이며, 기존 LLM의 언어 능력을 그대로 활용하면서도 시각 정보를 조건(condition)으로 자연스럽게 통합합니다. [논문]
2. BLIP VS Flamingo
BLIP은 이미지-텍스트를 함께 학습하는 Encoder-Decoder 기반 멀티모달 모델로, 이미지 캡셔닝·VQA 등을 위해 Vision Encoder와 Text Encoder/Decoder를 함께 학습(또는 파인튜닝)하는 구조인 반면, Flamingo는 대형 사전학습 LLM을 그대로 유지한 채 중간에 Cross-Attention 레이어를 삽입하여 시각 정보를 조건으로 주입하는 구조입니다. 즉, BLIP은 멀티모달을 위해 비교적 모델을 직접 학습·통합하는 방식이고, Flamingo는 강력한 LLM을 중심으로 이미지 정보를 “끼워 넣는” 방식에 가까우며, 특히 여러 이미지와 긴 문맥을 활용한 Few-shot 멀티모달 추론 능력이 강점이라는 점에서 구조적 철학과 활용 목적이 다릅니다.
3. Flamingo의 전체 구조
1. Vision Encoder (고정)
- 예: CLIP Vision Encoder
- 이미지 feature 추출
- Freeze (학습하지 않음)
2. Large Language Model (고정)
- 예: Chinchilla 기반 LLM
- 텍스트 생성 담당
- Freeze
3. Gated Cross-Attention Layer
- LLM 내부에 삽입
- 이미지 정보를 LLM에 주입
4. Flamingo의 특징
- 여러 장 이미지 입력
- 긴 텍스트 문맥 유지
- Few-shot 예시 기반 추론
[Image1] 이것은 고양이입니다.
[Image2] 이것은 강아지입니다.
[Image3] 이것은 무엇인가요?
반응형




