고정 헤더 영역
상세 컨텐츠
본문
반응형
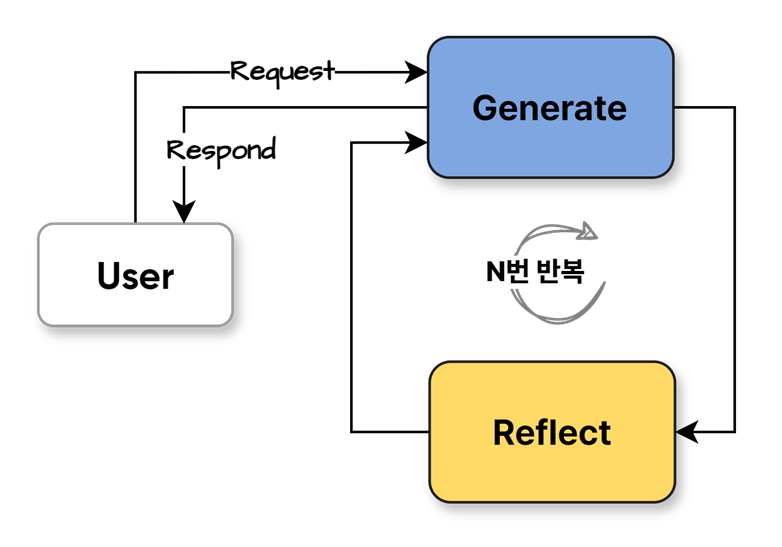
1. Reflection
Reflection은 에이전트가 스스로 결과를 평가·비판 한 뒤 그 피드백을 상태(state)에 기록하고, 필요하면 수정 루프로 되돌아가 답을 개선하는 설계 패턴입니다. 보통 “작성 노드(답 생성) → 리플렉션 노드(자기평가) → 라우팅(조건부 엣지)”로 구성되며, 리플렉션 노드는 품질 기준(예: 정확성, 근거, 형식)을 점수·코멘트(score, critique)로 남깁니다. 라우터는 이 정보를 읽어 임계값 미달이면 작성 노드로 되감기, 충족하면 종료 노드로 이동합니다. 무한 루프를 막기 위해 max_iters 같은 반복 한도를 두며, 툴 호출과는 별개로 LLM의 자기검토 능력을 활용해 코드 생성, 질의응답, 체인드 리저닝 등의 정확도·일관성을 높이는 데 쓰입니다.
import getpass
import os
def _set_env(var: str):
if not os.environ.get(var):
os.environ[var] = getpass.getpass(f"{var}: ")
_set_env("OPENAI_API_KEY")
!pip install langchain_openai
1. 가사 생성
from langchain_core.messages import AIMessage, BaseMessage, HumanMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"당신은 5단락 노래가사를 훌륭하게 작성하는 작사 도우미입니다."
"사용자의 요청에 따라 최고의 가사를 작성하세요."
"사용자가 피드백을 제공할 경우, 이전 시도에서 개선된 수정본을 작성해 응답하세요.",
),
MessagesPlaceholder(variable_name="messages"),
]
)
llm = ChatOpenAI(model="gpt-5-nano")
generate = prompt | llm
lyric = ""
request = HumanMessage(
content="이별에 대한 가사를 작성해주세요."
)
for chunk in generate.stream({"messages": [request]}):
print(chunk.content, end="")
lyric += chunk.content
2. 가사 개선
reflection_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"당신은 가사를 채점하는 작사가입니다. 사용자가 제출한 작사에 대한 비평과 개선 사항을 작성하세요."
"가사의 길이, 깊이, 문체 등을 포함해 구체적인 개선 요청을 제공하세요.",
),
MessagesPlaceholder(variable_name="messages"),
]
)
reflect = reflection_prompt | llm
reflection = ""
for chunk in reflect.stream({"messages": [request, HumanMessage(content=lyric)]}):
print(chunk.content, end="")
reflection += chunk.content
for chunk in generate.stream(
{"messages": [request, AIMessage(content=lyric), HumanMessage(content=reflection)]}
):
print(chunk.content, end="")
3. Graph로 Reflection 구현

!pip install langgraph
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import END, StateGraph, START
from langgraph.graph.message import add_messages
from langgraph.checkpoint.memory import MemorySaver
class State(TypedDict):
messages: Annotated[list, add_messages]
def generation_node(state: State) -> State:
return {"messages": [generate.invoke(state["messages"])]}
def reflection_node(state: State) -> State:
cls_map = {"ai": AIMessage, "human": HumanMessage}
# 첫번째 사용자 요청 + 생성메시지 (reflection_node's input)
# 첫번째 사용자 요청 + 생성메시지 + 피드백메시지 (generation_node's input)
# 첫번째 사용자 요청 + 생성메시지 + 피드백메시지 + 수정된 생성메시지 (reflection_node's input)
# 첫번째 사용자 요청 + 생성메시지 + 피드백메시지 + 수정된 생성메시지 + 피드백메시지 (generation_node's input)
# ...
translated = [state["messages"][0]] + [
cls_map[msg.type](content=msg.content) for msg in state["messages"][1:]
]
# translated = [state["messages"][0]] + [
# cls_map[msg.type](content=msg.content) for msg in state["messages"][-2:]
# ]
res = reflect.invoke(translated)
return {"messages": [HumanMessage(content=res.content)]}
graph_builder = StateGraph(State)
graph_builder.add_node("generate", generation_node)
graph_builder.add_node("reflect", reflection_node)
graph_builder.add_edge(START, "generate")
from typing import Literal
from langgraph.graph import END
def should_continue(state: State) -> Literal["reflect", END]:
if len(state["messages"]) > 6:
return END
return "reflect"
graph_builder.add_conditional_edges("generate", should_continue)
graph_builder.add_edge("reflect", "generate")
memory = MemorySaver()
graph = graph_builder.compile(checkpointer=memory)
graph
config = {"configurable": {"thread_id": "1"}}
for event in graph.stream(
{
"messages": [
HumanMessage(
content="이별에 대한 가사를 작성해주세요."
)
],
},
config,
):
print(event)
print("---")
state = graph.get_state(config)
ChatPromptTemplate.from_messages(state.values["messages"]).pretty_print()
2. Reflextion 구현
“Reflexion: Language Agents with Verbal Reinforcement Learning”은, 2023년 3월 20일 최초 제출, 2023년 10월 10일 v4로 개정된 논문입니다. 저자는 Noah Shinn 외 5명이고, 핵심 내용은 언어 에이전트가 스스로 언어적 피드백(반성문)을 생성·메모리에 저장해 다음 시도에 반영함으로써 성능을 높이는 프레임워크를 제안했다는 점입니다. HumanEval 등에서 유의미한 향상을 보고합니다.
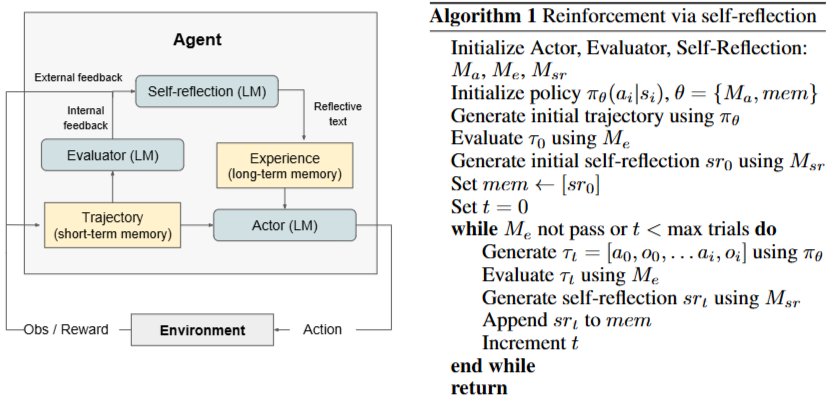
- Actor (LM): 실제 행동(답안 작성, 코드 생성 등)을 내는 언어모델입니다.
- Evaluator (LM): Actor가 낸 결과를 내부적으로 평가합니다(정확성·형식·테스트 통과 여부 판단 등).
- Self-reflection (LM): 평가 결과를 바탕으로 “다음에는 이렇게 고치자” 같은 반성문(Reflective text)을 만들어 냅니다.
- Trajectory (short-term memory): 이번 시도에서의 행동/관찰 기록(a₀, o₀, …)을 담는 단기 메모리입니다.
- Experience (long-term memory): 누적된 반성문을 쌓아두는 장기 메모리(mem)입니다. 이후 시도에서 프롬프트에 이 기억을 넣어 같은 실수를 반복하지 않게 합니다.
- Environment: 외부에서 관찰/보상(예: 유닛 테스트의 통과/실패, 웹툴의 응답 등)을 제공합니다. 외부 피드백이 있으면 Evaluator의 판단과 함께 사용됩니다.
def _set_env(var: str):
if not os.environ.get(var):
os.environ[var] = getpass.getpass(f"{var}: ")
_set_env("TAVILY_API_KEY")
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-5-nano")
!pip install langchain_community
!pip install langchain-tavily
from langchain_tavily import TavilySearch
tavily_tool = TavilySearch(max_results=5)
1. 필요한 데이터 클래스 정의
- Reflection - 놓친것 / 불필요한 것
from langchain_core.messages import HumanMessage, ToolMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from pydantic import BaseModel, Field
class Reflection(BaseModel):
missing: str = Field(description="누락되거나 부족한 부분에 대한 비평")
superfluous: str = Field(description="불필요한 부분에 대한 비평")
- AnswerQuestion - 답변 / 답변에 대한 반성 / 개선하기 위한 검색 쿼리
class AnswerQuestion(BaseModel):
answer: str = Field(description="질문에 대한 10문장 이내의 자세한 답변")
search_queries: list[str] = Field(
description="현재 답변에 대한 비평을 해결하기 위한 추가 조사를 위한 1~3개의 웹 검색 쿼리"
)
reflection: Reflection = Field(description="답변에 대한 자기반성 내용")
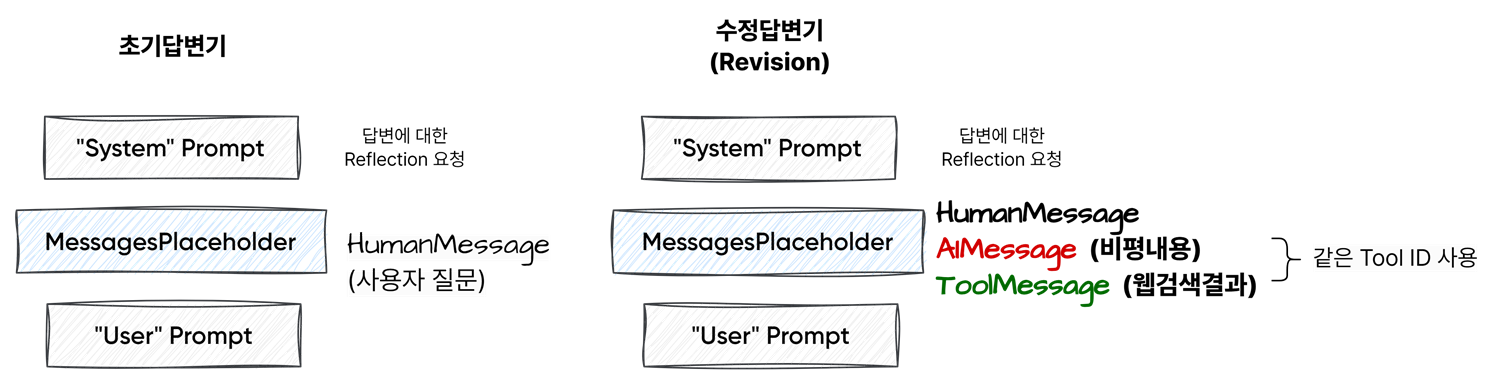
- Responder - 구조화된 출력을 위한 답변기
class Responder:
def __init__(self, runnable):
self.runnable = runnable # Chain
def respond(self, state: dict):
response = self.runnable.invoke(
{"messages": state["messages"]}
)
return {"messages": response}
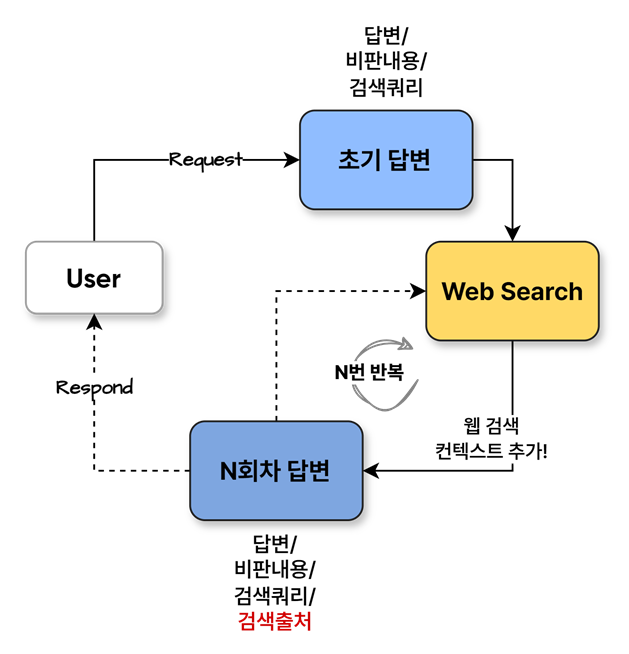
2. 초기 답변기 만들기 (Initial responder)
- 초기 답변을 위한 Chain 생성 -출력 스키마를 도구로 사용
import datetime
actor_prompt_template = ChatPromptTemplate.from_messages(
[
(
"system",
"""당신은 전문 연구자입니다.
1. {first_instruction}
2. <Reflect> 생성한 답변을 다시 되돌아보고 개선할 수 있도록 비판하세요.
3. <Recommend search queries> 답변의 질을 높이기 위해 추가적으로 조사해야 할 정보에 대한 웹 검색 쿼리를 추천하세요.""",
),
MessagesPlaceholder(variable_name="messages"),
(
"user",
"\n\n<Reflect> 사용자 원래 질문과 지금까지의 행동을 되돌아보세요."
),
]
)
initial_answer_chain = actor_prompt_template.partial(
first_instruction="질문에 대한 10문장 이내의 자세한 답변을 제공해주세요.", # 초기 답변
) | llm.bind_tools(tools=[AnswerQuestion], tool_choice="any")
llm_with_tool = llm.bind_tools(tools=[AnswerQuestion], tool_choice="any")
response = llm_with_tool.invoke([HumanMessage(content="AI Agent가 무엇인가요?")])
print(response)
response.tool_calls[0]['args']
first_responder = Responder(runnable=initial_answer_chain)
example_question = "AI Agent가 무엇인가요?"
initial = first_responder.respond(
{"messages": [HumanMessage(content=example_question)]}
)
initial
- tool 호출 결과 확인 (AnswerQuestion 에 맞춰 출력 생성)
initial["messages"].tool_calls[0]["args"]
3. 수정 단계(Revision)
class ReviseAnswer(AnswerQuestion):
"""Revise your original answer to your question. Provide an answer, reflection,
cite your reflection with references, and finally
add search queries to improve the answer."""
references: list[str] = Field(
description="업데이트된 답변에 사용된 인용 출처"
)
revise_instructions = """이전 답변을 새로운 정보를 바탕으로 수정하세요.
- 이전 비평 내용을 활용해 중요한 정보를 추가해야 합니다.
- 수정된 답변에는 반드시 숫자로 된 인용 표시를 포함하여 검증 가능하도록 해야 합니다.
- 답변 하단에 "참고문헌" 섹션을 추가하세요 (이 부분은 단어 수 제한에 포함되지 않습니다). 형식은 다음과 같습니다:
- [1] https://example.com
- [2] https://example.com
- 이전 비평 내용을 바탕으로 불필요한 정보를 제거하고, 최종 답변은 반드시 200자를 넘지 않도록 하세요.
"""
revision_chain = actor_prompt_template.partial(
first_instruction=revise_instructions,
) | llm.bind_tools(tools=[ReviseAnswer], tool_choice="any")
revisor = Responder(runnable=revision_chain)
- 초기답변에서 생성한 웹검색 쿼리를 Tool 실행한 결과를 함께 입력
import json
revised = revisor.respond(
{
"messages": [
HumanMessage(content=example_question),
initial["messages"],
ToolMessage(
tool_call_id=initial['messages'].additional_kwargs['tool_calls'][0]['id'],
content=json.dumps(
tavily_tool.invoke(
{
"query": initial["messages"].tool_calls[0]["args"]['search_queries'][0]
}
)
),
),
]
}
)
revised["messages"]
revised["messages"].tool_calls
4. 웹검색을 위한 툴 노드 생성
tavily_tool.batch(
[
{"query": initial["messages"].tool_calls[0]["args"]['search_queries'][0]}
]
)
from langchain_core.tools import StructuredTool
from langgraph.prebuilt import ToolNode
def run_queries(search_queries: list[str], **kwargs):
"""Run the generated queries."""
return tavily_tool.batch([{"query": query} for query in search_queries])
tool_node = ToolNode(
[
StructuredTool.from_function(run_queries, name=AnswerQuestion.__name__),
StructuredTool.from_function(run_queries, name=ReviseAnswer.__name__),
]
)
5. 그래프 생성하기
from langgraph.graph import END, StateGraph, START
from langgraph.graph.message import add_messages
from typing import Annotated
from typing_extensions import TypedDict
class State(TypedDict):
messages: Annotated[list, add_messages]
MAX_ITERATIONS = 5
graph_builder = StateGraph(State)
graph_builder.add_node("draft", first_responder.respond)
graph_builder.add_node("execute_tools", tool_node) # 웹 검색 진행
graph_builder.add_node("revise", revisor.respond)
graph_builder.add_edge("draft", "execute_tools")
graph_builder.add_edge("execute_tools", "revise")
def _get_num_iterations(state: list):
i = 0
for m in state[::-1]:
if m.type not in {"tool", "ai"}:
break
i += 1
return i
def event_loop(state: list):
num_iterations = _get_num_iterations(state["messages"])
if num_iterations > MAX_ITERATIONS:
return END
return "execute_tools"
graph_builder.add_conditional_edges("revise", event_loop, ["execute_tools", END])
graph_builder.add_edge(START, "draft")
graph = graph_builder.compile()
graph
events = graph.stream(
{"messages": [HumanMessage(content="AI Agent가 무엇인가요?")]},
stream_mode="values",
)
for i, step in enumerate(events):
print(f"Step {i}")
step["messages"][-1].pretty_print()
반응형
'인공지능 > AI Agent' 카테고리의 다른 글
| 쿼리문을 작성하는 RAG (0) | 2025.09.18 |
|---|---|
| 벡터 데이터베이스 (0) | 2025.09.17 |
| 랭그래프를 이용한 간단한 챗봇 (0) | 2025.09.09 |
| 랭그래프 기초 문법 (0) | 2025.09.08 |
| 랭그래프 (0) | 2025.09.07 |




