
신경망 기반의 벡터화
1. 워드 임베딩
워드 임베딩(Word Embedding)은 단어를 고차원의 희소 벡터로 표현하는 기존 방식(원-핫 인코딩) 대신, 단어의 의미를 저차원의 밀집 벡터(dense vector)로 변환하는 자연어 처리 기법입니다. 이를 통해 단어 간 유사성과 관계를 벡터 공간에 효율적으로 나타낼 수 있으며, 벡터 간의 거리 또는 방향을 통해 단어의 문맥적 의미를 학습합니다. 대표적인 워드 임베딩 알고리즘으로는 Embedding Layer, Word2Vec, GloVe, FastText 등이 있으며, 이를 사용하면 언어 모델이 문맥을 이해하거나 추론하는 데 필요한 기초적인 언어적 의미를 학습할 수 있습니다.
1. 램덤 초기화 임베딩
랜덤 초기화 임베딩은 모델 학습 초기 단계에서 임베딩 벡터를 무작위 값으로 설정한 후, 학습 데이터를 사용해 임베딩 값을 점진적으로 업데이트하는 방식입니다. 초기에는 각 단어의 벡터 표현이 의미를 가지지 않으며, 학습 과정에서 모델이 단어의 문맥적 의미를 학습하며 점차 유의미한 벡터를 형성합니다. 이 방식은 특정 도메인이나 언어의 특수성을 반영하기에 적합하며, 사전 훈련된 임베딩이 없는 경우나 사용자 정의 데이터를 기반으로 처음부터 학습해야 할 때 주로 사용됩니다.

2. 사전 훈련된 임베딩
사전 훈련된 임베딩은 대규모 코퍼스에서 미리 학습된 임베딩 벡터를 사용하여 초기 값을 설정하는 방식입니다. Word2Vec, GloVe, FastText 등과 같은 모델로 생성된 임베딩은 단어 간의 의미적 유사성을 잘 반영하며, 이를 활용하면 학습 초기에 좋은 성능을 얻을 수 있습니다. 사전 훈련된 임베딩은 학습 데이터가 부족하거나 일반적인 언어적 특징을 잘 반영해야 하는 상황에서 특히 유용합니다. 필요에 따라 임베딩 벡터를 고정하거나(frozen) 추가로 미세 조정(fine-tuning)하여 사용할 수 있습니다.
2. Embedding Layer
Embedding Layer는 신경망에서 단어를 밀집 벡터(dense vector)로 표현하기 위해 사용되는 층으로, 워드 임베딩(Word Embedding)을 수행하는 역할을 합니다. 이 레이어는 주어진 단어를 정수 인덱스로 매핑한 후, 해당 인덱스에 대응되는 고정 길이의 임베딩 벡터를 학습 가능한 파라미터로 초기화하여 반환합니다. 입력 크기가 크고 희소한 원-핫 인코딩 대신, 저차원의 임베딩 공간에서 단어의 의미적 관계를 효율적으로 학습하며, 이는 신경망의 가중치로 함께 학습됩니다. Embedding Layer는 주로 텍스트 데이터에서 단어를 벡터화하여 자연어 처리 모델(예: RNN, LSTM, Transformer)에 입력하기 위해 사용됩니다.
3. Word2Vec
Word2Vec은 단어를 벡터로 표현하기 위해 개발된 자연어 처리 기법으로, 단어 간의 의미적 유사성을 수치적으로 나타낼 수 있는 임베딩 벡터를 생성합니다. 주로 CBOW(Continuous Bag of Words)와 Skip-gram이라는 두 가지 모델 구조를 사용하며, CBOW는 주변 단어들을 기반으로 중심 단어를 예측하고, Skip-gram은 중심 단어를 기반으로 주변 단어들을 예측하는 방식입니다. 이 과정을 통해 학습된 임베딩 벡터는 단어 간의 문맥적 관계를 반영하며, 벡터 공간에서 유사한 의미를 가진 단어들이 서로 가깝게 위치합니다. Word2Vec은 대규모 코퍼스를 활용해 고성능 임베딩을 생성할 수 있으며, 자연어 처리 작업에서 사전 훈련된 임베딩으로 널리 사용됩니다. 벡터가 된 단어들은 연산이 가능합니다.
1. CBOW
CBOW(Continuous Bag of Words)는 자연어 처리에서 단어 임베딩을 학습하기 위해 사용되는 Word2Vec 알고리즘의 한 방법입니다. 이 모델은 주어진 문맥(즉, 중심 단어 주변의 단어들)을 기반으로 중심 단어를 예측하는 방식으로 작동합니다. 예를 들어, 문장에서 특정 단어의 좌우 몇 개 단어를 입력으로 받아 해당 중심 단어를 출력으로 예측하는 구조입니다. 이를 통해 단어 간의 문맥적 관계를 효과적으로 학습할 수 있으며, 단어를 고차원 공간의 벡터로 표현하여 의미적으로 유사한 단어들이 가까운 위치에 있도록 학습됩니다. CBOW는 연산적으로 효율적이며, 대규모 데이터에서 빠르고 안정적으로 임베딩을 생성할 수 있다는 장점이 있습니다.
문장 예제
"나는 오늘 공원에서 귀여운 강아지를 산책시키며 행복한 시간을 보냈다."
2. Skip-gram
Skip-gram은 Word2Vec 알고리즘의 한 방법으로, 주어진 중심 단어로부터 주변 문맥 단어들을 예측하는 방식으로 작동합니다. 즉, 중심 단어를 입력으로 사용하고, 그 단어를 기준으로 설정된 윈도우 크기 내에 있는 주변 단어들을 출력으로 예측합니다. 예를 들어, 문장에서 "고양이"라는 단어가 중심 단어라면, 그 주변 단어들(예: "귀여운", "자는")을 예측하는 식입니다. Skip-gram은 희소한 데이터에서도 성능이 우수하며, 특히 드문 단어의 문맥적 의미를 학습하는 데 효과적입니다. 이 모델은 단어의 의미적 관계를 더 잘 반영한 고품질의 단어 벡터를 생성할 수 있지만, CBOW에 비해 계산량이 더 많다는 특징이 있습니다.
문장 예제
"나는 오늘 공원에서 귀여운 강아지를 산책시키며 행복한 시간을 보냈다."







3. SGNS
SGNS(Skip-Gram with Negative Sampling)는 Skip-gram 모델의 변형으로, 단어 임베딩을 효율적으로 학습하기 위해 네거티브 샘플링(Negative Sampling) 기법을 사용합니다. 기본 Skip-gram은 중심 단어로 주변의 모든 문맥 단어를 예측해야 하지만, SGNS는 주변 단어와의 관계를 일부 샘플로만 학습하여 계산 비용을 줄입니다. 즉, 중심 단어와 실제 문맥 단어 쌍(정답)을 학습하면서, 무작위로 선택된 단어(네거티브 샘플)들과의 관계를 "연관성이 없다"고 학습시킵니다. 이를 통해 모델은 중심 단어와 문맥 단어 간의 의미적 관계를 효과적으로 학습하면서도 연산량을 크게 줄일 수 있습니다. SGNS는 Word2Vec 알고리즘에서 널리 사용되며, 실제로 가장 보편적인 단어 임베딩 학습 방법으로 자리 잡았습니다.
문장 예제
"나는 오늘 공원에서 귀여운 강아지를 산책시키며 행복한 시간을 보냈다."




import gensim
gensim.__version__
※ Gensim
Gensim은 자연어 처리를 위한 파이썬 기반의 오픈소스 라이브러리로, 특히 문서와 단어 임베딩 및 주제 모델링 작업에 적합합니다. Gensim은 효율적이고 확장 가능한 방식으로 Word2Vec, Doc2Vec, FastText 등의 임베딩 모델과 LDA(Latent Dirichlet Allocation) 같은 주제 모델링 알고리즘을 지원합니다. 이 라이브러리는 대규모 텍스트 데이터에서도 빠르게 학습할 수 있도록 최적화되어 있으며, 스트리밍 방식으로 메모리 효율적으로 데이터를 처리할 수 있습니다. Gensim은 간단한 API를 제공해 연구와 실제 프로젝트에서 사용하기 쉽고, 텍스트의 의미적 관계를 학습하거나 토픽 분류, 문서 추천 등 다양한 작업에 활용됩니다.
import urllib
urllib.request.urlretrieve("https://raw.githubusercontent.com/GaoleMeng/RNN-and-FFNN-textClassification/master/ted_en-20160408.xml", filename="ted_en-20160408.xml")
※ TED Talks의 자막 데이터
ted_en-20160408.xml 데이터는 TED Talks의 자막 데이터를 XML 형식으로 저장한 파일입니다. 이 데이터는 주로 자연어 처리(NLP) 및 기계 학습 프로젝트에서 텍스트 데이터로 활용됩니다. 이 파일은 다양한 TED 강연의 영어 자막을 포함하고 있으며, 각 강연의 텍스트와 메타데이터가 포함되어 있습니다.
XML 파일 내부의 데이터는 다음과 같은 구조로 이루어져 있습니다.
<file>
<head>
<url>http://www.ted.com/talks/ken_robinson_says_schools_kill_creativity</url>
<pagesize>12345</pagesize>
<title>Ken Robinson: Do schools kill creativity?</title>
</head>
<content>
<p>Good morning. How are you? It's been great, hasn't it? I've been blown away by the whole thing.</p>
<p>In fact, I'm leaving.</p>
...
</content>
</file>
from lxml import etree
targetXML = open('ted_en-20160408.xml', 'r', encoding='UTF8')
target_text = etree.parse(targetXML)
root = target_text.getroot() # 루트 요소 가져오기
# XML 파일의 앞부분(루트 노드 포함)을 일부만 출력
xml_string = etree.tostring(root).decode('utf-8')
print('\n'.join(xml_string.split('\n')[:20]))
# xml 파일로부터 <content>와 </content> 사이의 내용만 가져온다.
parse_text = '\n'.join(target_text.xpath('//content/text()'))
parse_text
# 정규 표현식의 sub 모듈을 통해 content 중간에 등장하는 (Audio), (Laughter) 등의 배경음 부분을 제거.
# 해당 코드는 괄호로 구성된 내용을 제거.
import re
content_text = re.sub(r'\([^)]*\)', '', parse_text)
len(content_text)
import nltk
from nltk.tokenize import sent_tokenize
nltk.download('punkt_tab')
# 입력 코퍼스에 대해서 NLTK를 이용하여 문장 토큰화를 수행.
sent_text = sent_tokenize(content_text)
sent_text[:2]
# 각 문장에 대해서 구두점을 제거하고, 대문자를 소문자로 변환.
normalized_text = []
for string in sent_text:
tokens = re.sub(r"[^a-z0-9]+", " ", string.lower())
normalized_text.append(tokens)
# 각 문장에 대해서 NLTK를 이용하여 단어 토큰화를 수행.
result = [word_tokenize(sentence) for sentence in normalized_text]
print('총 샘플의 개수 : {}'.format(len(result)))for line in result[:3]: # 샘플 3개만 출력
print(line)
from gensim.models import Word2Vec
# vector_size = 워드 벡터의 특징 값. 즉, 임베딩 된 벡터의 차원.
# window = 컨텍스트 윈도우 크기
# min_count = 단어 최소 빈도 수 제한 (빈도가 적은 단어들은 학습하지 않는다.)
# workers = 학습을 위한 프로세스 수
# sg = 0은 CBOW, 1은 Skip-gram.
model = Word2Vec(sentences=result, vector_size=100, window=5, min_count=5, workers=4, sg=0)
model_result = model.wv.most_similar("man")
print(model_result)
model.wv["man"]
len(model.wv["man"])
from gensim.models import KeyedVectors
model.wv.save_word2vec_format('eng_w2v') # 모델 저장
loaded_model = KeyedVectors.load_word2vec_format("eng_w2v") # 모델 로드
model_result = loaded_model.most_similar("man")
print(model_result)
print(model.wv.vectors.shape)
4. NSMC 데이터셋
NSMC(Naver Sentiment Movie Corpus)는 네이버 영화 리뷰를 기반으로 구축된 한국어 감성 분석 데이터셋으로, 총 200,000개의 리뷰가 포함되어 있습니다. 각 리뷰는 긍정(1) 또는 부정(0) 레이블이 지정되어 있어 감성 분석(Sentiment Analysis) 모델을 학습하는 데 활용됩니다. NSMC는 한국어 자연어 처리(NLP) 연구 및 머신러닝 모델 훈련에 널리 사용되며, 데이터의 균형이 잘 맞춰져 있어 높은 성능의 감성 분석 모델을 구축하는 데 유용합니다. 이 데이터셋은 공개되어 있어, ratings.txt 등의 파일 형식으로 쉽게 다운로드하여 활용할 수 있습니다.
# KoNLPy의 OKT 등은 형태소 분석 속도가 너무 느림
# 단, Mecab은 형태소 분석 속도는 빠르지만 설치하는데 시간이 많이 걸림
!pip install konlpy
!pip install mecab-python
!bash <(curl -s https://raw.githubusercontent.com/konlpy/konlpy/master/scripts/mecab.sh)
import urllib.request
from konlpy.tag import Mecab
from gensim.models.word2vec import Word2Vec
import pandas as pd
import matplotlib.pyplot as plt
urllib.request.urlretrieve("https://raw.githubusercontent.com/e9t/nsmc/master/ratings.txt", filename="ratings.txt")
train_data = pd.read_table('ratings.txt')
train_data[:5] # 상위 5개 출력
print(len(train_data)) # 리뷰 개수 출력
# NULL 값 존재 유무
print(train_data.isnull().values.any())
train_data = train_data.dropna(how = 'any') # Null 값이 존재하는 행 제거
print(train_data.isnull().values.any()) # Null 값이 존재하는지 확인
print(len(train_data)) # 리뷰 개수 출력
# 정규 표현식을 통한 한글 외 문자 제거
train_data['document'] = train_data['document'].str.replace("[^ㄱ-ㅎㅏ-ㅣ가-힣 ]","")
train_data[:5] # 상위 5개 출력
# 불용어 정의
stopwords = ['도', '는', '다', '의', '가', '이', '은', '한', '에', '하', '고', '을', '를', '인', '듯', '과', '와', '네', '들', '듯', '지', '임', '게']
※ 불용어
불용어(Stopwords)는 자연어 처리(NLP)에서 의미를 분석하는 데 큰 영향을 주지 않는 단어들을 의미하며, 주로 자주 등장하지만 중요한 의미를 갖지 않는 단어들을 제거할 때 사용됩니다. 예를 들어, 한국어에서는 "이", "그", "저", "그리고", "하지만"과 같은 접속사나 조사 등이 포함되며, 영어에서는 "is", "the", "and", "in" 등이 대표적인 불용어입니다. 불용어를 제거하면 텍스트 데이터의 크기를 줄이고, 핵심적인 단어들에 집중할 수 있어 감성 분석, 문서 분류 등의 NLP 작업에서 모델의 성능을 향상시키는 데 도움이 됩니다.
mecab = Mecab()
tokenized_data = []
for sentence in train_data['document']:
temp_X = mecab.morphs(sentence) # 토큰화
temp_X = [word for word in temp_X if not word in stopwords] # 불용어 제거
tokenized_data.append(temp_X)
print(tokenized_data[:3])
from gensim.models import Word2Vec
model = Word2Vec(sentences = tokenized_data, vector_size = 100, window = 5, min_count = 5, workers = 4, sg = 0)
# 완성된 임베딩 매트릭스의 크기 확인
model.wv.vectors.shape
print(model.wv.most_similar("블록버스터"))
model.wv['블록버스터']
from gensim.models import KeyedVectors
model.wv.save_word2vec_format('kor_w2v') # 모델 저장
4. FastText
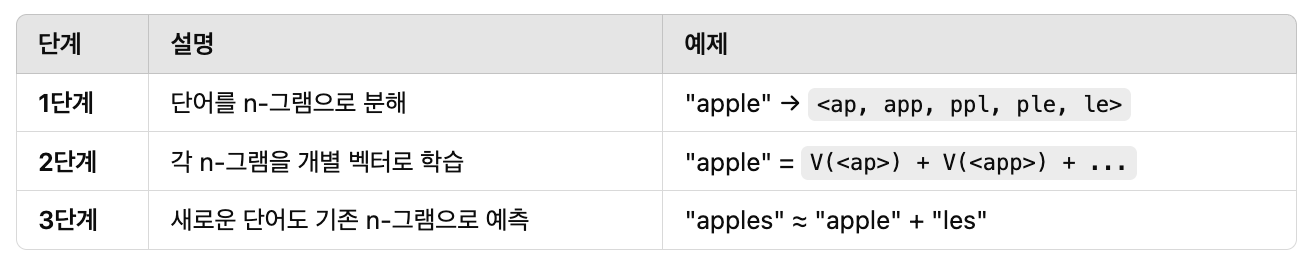
FastText는 Facebook AI Research(FAIR)에서 개발한 단어 임베딩 및 텍스트 분류 모델로, Word2Vec과 유사하지만 서브워드(subword) 정보를 활용하여 더 강력한 성능을 제공합니다. 기존의 단어 임베딩 기법들은 단어 단위로 벡터를 학습하지만, FastText는 단어를 여러 개의 n-그램 문자 조각(character n-grams)으로 분해하여 학습하기 때문에 희귀 단어(OOV, Out-of-Vocabulary) 처리와 형태소 기반 언어(예: 한국어)에서 뛰어난 성능을 보입니다. 또한, FastText는 텍스트 분류에도 활용 가능하며, 빠른 속도와 높은 성능 덕분에 감성 분석, 문서 분류, 검색 시스템 등 다양한 자연어 처리(NLP) 작업에서 널리 사용됩니다.
loaded_model = KeyedVectors.load_word2vec_format("eng_w2v") # Word2Vec 모델 로드
model_result = loaded_model.most_similar("ryuzy")
print(model_result)
model_result = loaded_model.most_similar("memory")
print(model_result)
from gensim.models import FastText
# gensim.models.FastText를 사용하여 FastText 모델을 학습
# vector_size: 생성할 단어 벡터의 차원 수
# window: 컨텍스트 윈도우 크기를 설정. 현재 단어를 기준으로 좌우 몇 개의 단어를 고려할지 정하는 값
# min_count: 코퍼스에서 등장 횟수가 min_count 미만인 단어를 무시
# workers: 병렬 처리를 위한 CPU 코어 개수를 설정
# sg: 학습 알고리즘을 결정하는 Skip-gram(1) / CBOW(0) 선택 옵션
fasttext_model = FastText(result, vector_size=100, window=5, min_count=5, workers=4, sg=1)
fasttext_model.wv.most_similar('ryuzy')
fasttext_model.wv.most_similar('memorry')
네이버 쇼핑 리뷰 데이터셋
네이버 쇼핑 리뷰 데이터를 포함하는 텍스트 파일로, 주로 감성 분석(Sentiment Analysis) 연구에 활용됩니다. 이 데이터셋에는 각 리뷰의 내용과 해당 리뷰의 긍정(1) 또는 부정(0) 여부가 라벨로 포함되어 있습니다. 텍스트 데이터와 감성 레이블이 짝을 이루고 있어 자연어 처리(NLP) 모델을 훈련하는 데 적합하며, 특히 딥러닝 기반 감성 분석 모델 개발 및 성능 평가에 유용합니다. 데이터의 구조는 일반적으로 탭(\t)으로 구분된 두 개의 열(리뷰 텍스트, 감성 라벨)로 구성되어 있으며, 한국어 텍스트 분석 실험에서 널리 사용됩니다.
urllib.request.urlretrieve("https://raw.githubusercontent.com/bab2min/corpus/master/sentiment/naver_shopping.txt", filename="ratings_total.txt")
total_data = pd.read_table('ratings_total.txt', names=['ratings', 'reviews'])
print('전체 리뷰 개수 :',len(total_data))
total_data[:5]
# 한글 자모 단위 처리 패키지 설치
!pip install hgtk
import hgtk
# 한글인지 체크
hgtk.checker.is_hangul('ㄱ')
# 한글인지 체크
hgtk.checker.is_hangul('28')
# 음절을 초성, 중성, 종성으로 분해
hgtk.letter.decompose('남')
# 초성, 중성을 결합
hgtk.letter.compose('ㄴ', 'ㅏ')
# 초성, 중성, 종성을 결합
hgtk.letter.compose('ㄴ', 'ㅏ', 'ㅁ')
# 한글이 아닌 입력에 대해서는 에러 발생.
hgtk.letter.decompose('1')
# 결합할 수 없는 상황에서는 에러 발생
hgtk.letter.compose('ㄴ', 'ㅁ', 'ㅁ')
def word_to_jamo(token):
def to_special_token(jamo):
if not jamo:
return '-'
else:
return jamo
decomposed_token = ''
for char in token:
try:
# char(음절)을 초성, 중성, 종성으로 분리
cho, jung, jong = hgtk.letter.decompose(char)
# 자모가 빈 문자일 경우 특수문자 -로 대체
cho = to_special_token(cho)
jung = to_special_token(jung)
jong = to_special_token(jong)
decomposed_token = decomposed_token + cho + jung + jong
# 만약 char(음절)이 한글이 아닐 경우 자모를 나누지 않고 추가
except Exception as exception:
if type(exception).__name__ == 'NotHangulException':
decomposed_token += char
# 단어 토큰의 자모 단위 분리 결과를 추가
return decomposed_token
word_to_jamo('남동생')
# '여동생'의 경우 여에 종성이 없으므로 종성의 위치에 특수문자 '-'가 대신 들어감
word_to_jamo('여동생')
mecab = Mecab()
print(mecab.morphs('선물용으로 빨리 받아서 전달했어야 하는 상품이었는데 머그컵만 와서 당황했습니다.'))
def tokenize_by_jamo(s):
return [word_to_jamo(token) for token in mecab.morphs(s)]
print(tokenize_by_jamo('선물용으로 빨리 받아서 전달했어야 하는 상품이었는데 머그컵만 와서 당황했습니다.'))
from tqdm import tqdm
tokenized_data = []
for sample in total_data['reviews'].to_list():
tokenzied_sample = tokenize_by_jamo(sample) # 자소 단위 토큰화
tokenized_data.append(tokenzied_sample)
tokenized_data[0]
def jamo_to_word(jamo_sequence):
tokenized_jamo = []
index = 0
# 1. 초기 입력
# jamo_sequence = 'ㄴㅏㅁㄷㅗㅇㅅㅐㅇ'
while index < len(jamo_sequence):
# 문자가 한글(정상적인 자모)이 아닐 경우
if not hgtk.checker.is_hangul(jamo_sequence[index]):
tokenized_jamo.append(jamo_sequence[index])
index = index + 1
# 문자가 정상적인 자모라면 초성, 중성, 종성을 하나의 토큰으로 간주.
else:
tokenized_jamo.append(jamo_sequence[index:index + 3])
index = index + 3
# 2. 자모 단위 토큰화 완료
# tokenized_jamo : ['ㄴㅏㅁ', 'ㄷㅗㅇ', 'ㅅㅐㅇ']
word = ''
try:
for jamo in tokenized_jamo:
# 초성, 중성, 종성의 묶음으로 추정되는 경우
if len(jamo) == 3:
if jamo[2] == "-":
# 종성이 존재하지 않는 경우
word = word + hgtk.letter.compose(jamo[0], jamo[1])
else:
# 종성이 존재하는 경우
word = word + hgtk.letter.compose(jamo[0], jamo[1], jamo[2])
# 한글이 아닌 경우
else:
word = word + jamo
# 복원 중(hgtk.letter.compose) 에러 발생 시 초기 입력 리턴.
# 복원이 불가능한 경우 예시) 'ㄴ!ㅁㄷㅗㅇㅅㅐㅇ'
except Exception as exception:
if type(exception).__name__ == 'NotHangulException':
return jamo_sequence
# 3. 단어로 복원 완료
# word : '남동생'
return word
jamo_to_word('ㄴㅏㅁㄷㅗㅇㅅㅐㅇ')
jamo_to_word('ㅇㅕ-ㄷㅗㅇㅅㅐㅇ')
with open('tokenized_data.txt', 'w') as out:
for line in tqdm(tokenized_data, unit=' line'):
out.write(' '.join(line) + '\n')
!pip install fasttext
import fasttext
model = fasttext.train_unsupervised('tokenized_data.txt', model='cbow')
model.save_model("fasttext.bin")
model = fasttext.load_model("fasttext.bin")
model[word_to_jamo('남동생')] # 'ㄴㅏㅁㄷㅗㅇㅅㅐㅇ'=
model.get_nearest_neighbors(word_to_jamo('남동생'), k=10)
def transform(word_sequence):
return [(jamo_to_word(word), similarity) for (similarity, word) in word_sequence]
print(transform(model.get_nearest_neighbors(word_to_jamo('남동생'), k=10)))
print(transform(model.get_nearest_neighbors(word_to_jamo('남동쉥'), k=10)))
print(transform(model.get_nearest_neighbors(word_to_jamo('남동셍ㅋ'), k=10)))
print(transform(model.get_nearest_neighbors(word_to_jamo('난동생'), k=10)))
print(transform(model.get_nearest_neighbors(word_to_jamo('낫동생'), k=10)))
print(transform(model.get_nearest_neighbors(word_to_jamo('납동생'), k=10)))
print(transform(model.get_nearest_neighbors(word_to_jamo('냚동생'), k=10)))
print(transform(model.get_nearest_neighbors(word_to_jamo('제품^^'), k=10)))
5. GloVe
GloVe(Global Vectors for Word Representation)는 Stanford University에서 개발한 단어 임베딩 기법으로, 단어의 의미를 벡터 형태로 표현하는 방법입니다. GloVe는 단순한 윈도우 기반의 주변 단어 관계를 학습하는 Word2Vec과 달리, 전체 코퍼스에서 동시 발생 행렬(Co-occurrence Matrix)을 기반으로 단어 간의 통계적 관계를 학습합니다. 즉, 단어와 단어가 함께 등장하는 빈도를 분석하여 의미적으로 유사한 단어들이 가까운 벡터 공간에서 배치되도록 합니다. 이러한 방식은 단어 간의 유사성을 효과적으로 캡처할 뿐만 아니라, 선형 관계(예: "king - man + woman ≈ queen")도 잘 반영합니다. GloVe는 사전 학습된 벡터를 제공하여 NLP 태스크에서 전이 학습이 가능하며, 감성 분석, 기계 번역 등 다양한 자연어 처리 작업에 활용됩니다. 논문
동시 발생 행렬 만들기
I like deep learning.
I like NLP.
I enjoy learning NLP.

